挑战/密码分析:单字母替换 - Polybius [Root Me:专注于黑客与信息安全的学习平台]
最近一直在学密码学,但是大多理论知识太过枯燥,所以就直接找了些密码学相关题进行学习研究,理论为辅,实战为主!固定复盘习惯,防止刷完就忘,所以便想着记录下来,开始沉淀属于自己的密码学知识体系!
一个奇怪的人在买了一卷来源可疑的卷轴后联系了你......他指望你敏锐的头脑来解读这条信息!你必须动用所有密码分析能力。
题目相关资料里有一个 PDF:

PDF 的核心主题是 Le carré de Polybe,也就是 Polybius square / 波利比奥斯方阵。
PDF浅析:它把 Polybius 方阵归类为一种很基础的 单表替换密码 ->就是每个明文字母都有一个固定替换结果,并且在全文中保持不变。
文章不需要看的很懂,只需要知道这道题考的啥?命题中的(他指望你敏锐的头脑来解读这条信息!)就是需要把这段密文解密出来就行了,具体考的啥加密,PDF也写的很明白了(Polybius)
波利比奥斯方阵(Polybius Square)是一种经典的加密方法,最早由古希腊学者波利比奥斯提出。它的基本原理是通过一个方阵,将字母与数字(通常是2位数字)对应起来,从而实现加密和解密。加密时,明文中的每个字母都被替换为方阵中对应字母的行和列的坐标。解密时,接收到的数字坐标会根据预设的方阵找到对应的字母。
确定字母表、行数和列数: 在加密之前,首先需要确定字母表(支持多种语言)、行数和列数;同时,还可以选择使用的分隔符(例如,逗号、空格等)。
生成方阵: 根据字母表、行数和列数,自动生成对应的波利比奥斯方阵,方阵中每个字符都会被分配一个行列坐标。
加密过程:将明文中的每个字母按照行列坐标替换,结果是用数字对(行列坐标)来表示明文。
输出密文: 最终的密文是由数字对组成的字符串。
对于标准的26个英文字母“ABCDEFGHIJKLMNOPQRSTUVWXYZ”,通常使用5行5列的方阵:
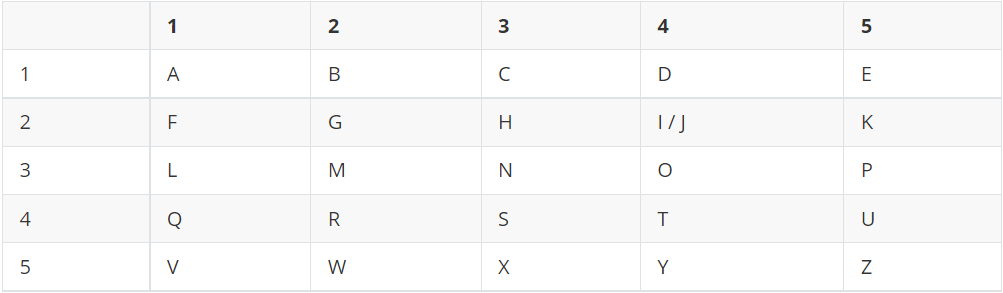
明文“HELLO”的加密过程:
H -> (2, 3)
E -> (1, 5)
L -> (3, 1)
L -> (3, 1)
O -> (3, 4)
所以,“HELLO”加密后的密文是“23 15 31 31 34”。
确定字母表、行数和列数: 解密时,首先需要知道字母表、行数和列数,以便构建正确的方阵。
解析数字对: 密文是由数字对(行列坐标)组成的,每个数字对对应一个字母。根据密文中的数字对,在方阵中查找相应的字母。
输出明文:把查找到的字母组合起来输出最终的明文。
如果收到密文“23 15 31 31 34”,根据上述方阵查找:
23 -> H
15 -> E
31 -> L
31 -> L
34 -> O
解密后的明文是:HELLO。
加密和解密流程:
PDF 对这个方法的思路可以概括成两步。
加密时:
先准备一个 5x5 字母表。
找到每个明文字母所在的位置。
用“行号 + 列号”替换这个字母。
解密时反过来:
把密文按两个字符一组拆开。
每组坐标定位到方阵里的一个格子。
读出格子里的字母。
所以只要看到一串东西像这样:
11 22 35 44 15或者像本题这样:
b3 a3 d1 c2 b1第一反应就应该是:它可能不是普通文本,而是坐标。
a b c d e
1 2 3 4 5这非常像一个改写版的 5x5 坐标系统:
1 2 3 4 5
+-----------------------
a | a1 | a2 | a3 | a4 | a5
b | b1 | b2 | b3 | b4 | b5
c | c1 | c2 | c3 | c4 | c5
d | d1 | d2 | d3 | d4 | d5
e | e1 | e2 | e3 | e4 | e5也就是说,题目把传统的:
11 12 13 14 15
21 22 23 24 25
...改成了:
a1 a2 a3 a4 a5
b1 b2 b3 b4 b5
...所以 b3a3d1 不应该看成 6 个独立字符,而应该拆成:
b3 / a3 / d1这一步就是本题最重要的前置判断。
本题的坐标和明文字母之间不是标准顺序,而是被重新打乱过。而且笔者还拿去对应网站试过,是无法直接套出来的
根据最终的密文分析出:
b3 -> c
a3 -> e
d1 -> s如果按普通标准表,b3 应该是等于12 3。这说明题目不是单纯的标准 Polybius,而是:
Polybius 坐标外壳 + 打乱后的单表替换前置文件只能帮我们识别“它是坐标型密文”,但不能直接给出最终明文。真正解题还需要做频率分析。题目的核心思路只有三步:
先识别密文的最小单位不是单个字符,而是像 b3 这样的坐标对。
再利用法语高频词,把这些坐标对还原成明文字母。
最后把整篇密文回代,解密那段密文得到明文便可得到flag!
结构分析:
先看密文长什么样
题目文件里的内容大概是这样:
b3a3d1 c2b1e3d4d3d1 a4e5c5b1e3c2a3d1 ...先注意两个现象:
里面只出现 a-e 和 1-5。
每个“词”长度几乎都是偶数。
这说明它不是普通字母表,而是把“一个字母”编码成了“两个字符”的坐标。
比如:
b3a3d1 -> [b3][a3][d1]也就是说,真正的解密单位是 b3、a3、d1 这种二元坐标。
1 2 3 4 5
+-----------------------
a | a1 | a2 | a3 | a4 | a5
b | b1 | b2 | b3 | b4 | b5
c | c1 | c2 | c3 | c4 | c5
d | d1 | d2 | d3 | d4 | d5
e | e1 | e2 | e3 | e4 | e5在这种写法里,b3 就表示“第 b 行,第 3 列”。 题目给你的密文,实际上就是把明文字母替换成了这种坐标。
注意:本题里并不是所有格子都被用到,e4 没有出现,所以咱们不需要去分析未被使用过的密文
在整篇密文里,每个符号始终对应同一个明文字母。 例如如果 e3 代表 a,那么全文里所有 e3 都应该还是 a。
法语里 e 出现特别多。
常见短词有 de、et、la、le、que。
单字母词在法语里也很有用,比如 a。
所以只要统计密文里“谁最常见、谁是短词、谁的重复模式像法语”,就能开始反推。
先抓最明显的词:
这里一定要分清两个统计对象:
坐标频率:统计 a3、d1、e5 等等这种单个高频坐标出现了多少次。
词频:统计 d3a3、c4e3、a3a1 等等这种高频完整密文词出现了多少次。
通过代码计算汇总,坐标频率最高的几个是:
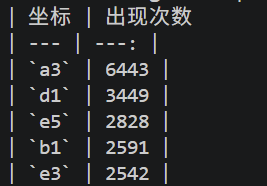
import re
from collections import Counter
from pathlib import Path
# 读取密文文件
text = Path("ch12.txt").read_text(encoding="utf-8")
# 提取所有坐标对,比如 a3、d1、e5
pairs = re.findall(r"[a-e][1-5]", text)
# 统计频率
counter = Counter(pairs)
# 输出前 5 个
print("| 坐标 | 出现次数 ")
print("| --- | ---: |")
for pair, count in counter.most_common(5):
print(f"| `{pair}` | {count} |")通过代码计算汇总,词频最高的几个是:
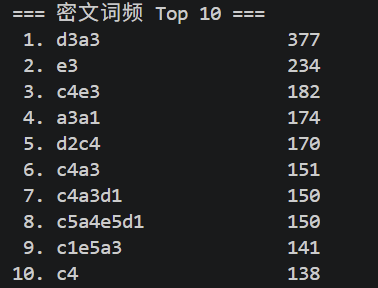
import re
from collections import Counter
from pathlib import Path
text = Path("ch12.txt").read_text(encoding="utf-8")
# 提取完整密文词
words = re.findall(r"(?:[a-e][1-5])+", text)
# 统计词频
counter = Counter(words)
# 输出前 10 个最高频密文词
print("=== 密文词频 Top 10 ===")
for i, (word, freq) in enumerate(counter.most_common(10), 1):
print(f"{i:2}. {word:20} {freq}")笔者这次采用的方法,不是直接凭感觉猜字母,而是“先统计、再筛选、再打分、最后回代验证”。就是先用代码统计密文里哪些坐标、哪些短词最常出现,再把这些高频坐标与法语里常见的高频字母、高频功能词做候选匹配,看哪一种映射能同时解释更多高频词,最后再把得分最高的候选回代到原文中,检查是否能形成通顺的法语句子。
上ai联网搜索法语频率排行榜:
排名 字符 出现频率
1 e 14.47%
2 s 7.98%
3 a 7.60%
4 n 7.32%
5 i 7.21%
6 t 7.11%
7 r 6.86%
8 l 5.86%
9 u 5.55%
10 o 5.39%
11 d 4.08%
12 c 3.39%
13 p 2.98%
14 m 2.78%
15 é 2.43%
16 v 1.29%
17 g 1.18%
18 f 1.12%
19 b 0.96%
20 h 0.93%
21 q 0.85%
22 à 0.43%
23 x 0.43%
24 è 0.42%
25 y 0.34%
26 j 0.30%
27 k 0.16%
28 ê 0.13%
29 z 0.10%
30 w 0.08%
31 â 0.05%
32 ç 0.05%
33 ô 0.05%
34 î 0.04%
35 œ 0.02%
36 ù 0.02%
37 û 0.02%
38 ï 0.01%我们真正已经知道的事实只有两个:
a3 是全文出现次数最多的坐标,频次是 6443。
单表替换会保留“谁最常出现”这个整体趋势。那么可以根据ai联网搜索的排行榜:假设a3 为e,不过呢这里仍然不是最终证明;它只是“最优先验证的候选映射”。真正让这个判断成立的,不是这一步本身,而是它带来的后续连锁验证。
上ai联网搜索与e结合的高频词排行榜:
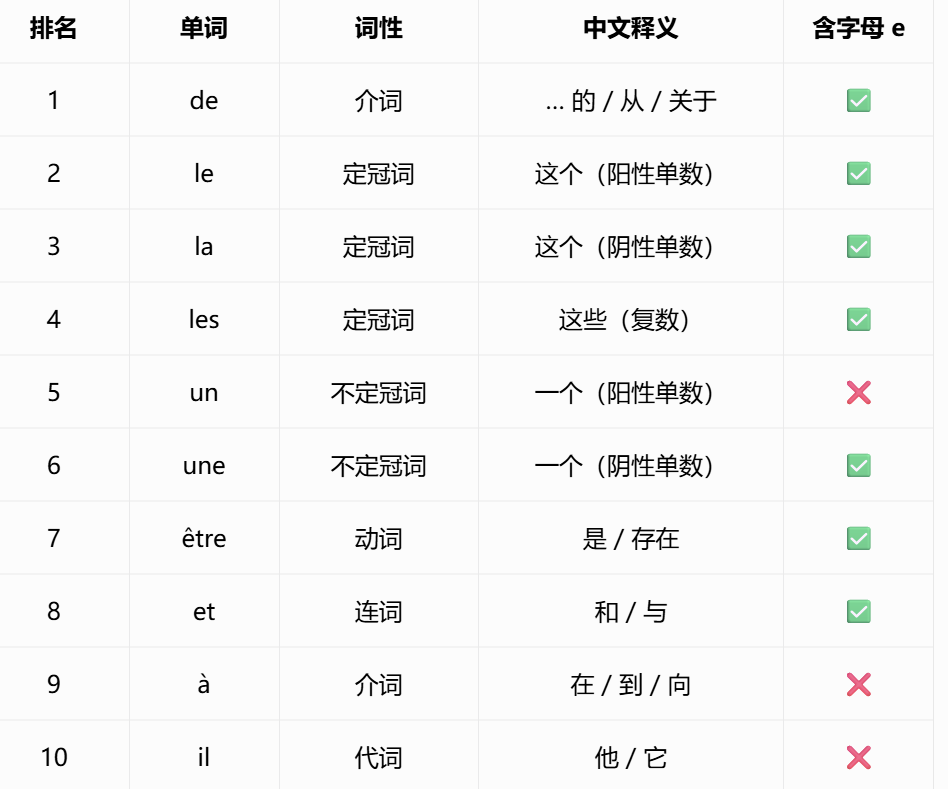
假如a3 = e,则最高频双坐标词通过高频对比:d3a3 -->de
假如a3 = e,则a3a1变成 e?通过高频对比:--> et
把这些结果继续回代到开头句子里,还能推出一整串正常法语
代码统计先证明 a3 是最高频坐标,法语字母频率说明最高频坐标最值得优先验证成 e,后续词频和整句回代再把这个假设验证为成立,最终能得到以下表:
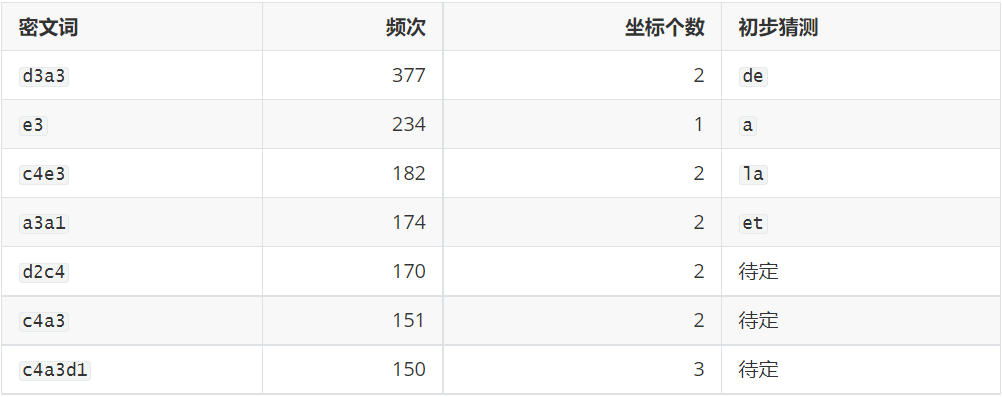
这张表才是真正开始破题的地方。
d3a3 是全篇最高频的双坐标词,频次 377。如果把前面的统计结论 a3 = e 带进去,它就变成 ?e。法语正文里最常见、最值得优先验证的两字母词之一就是 de,所以首先检查 d3a3 = de 是否成立;一旦成立,就能得到 d3 = d。
e3 是一个单坐标词,频次 234。法语里常见单字母词主要是 a、y,而在这种散文正文里 a 的频率通常远高于 y,所以 e3 = a 是更优先验证的候选。
c4e3 出现 182 次。如果前一步 e3 = a 成立,那么它的形状就是 ?a。法语高频短词里,最常见且最值得先检验的就是 la,因此再验证 c4 = l。
a3a1 出现 174 次。如果 a3 = e 已经被前两步支持,那么它就变成 e?。法语里最常见的两字母高频词之一就是 et,因此可继续验证 a1 = t。
这时我们已经有了一批比较稳的基础映射:
a3 = e
d3 = d
e3 = a
c4 = l
a1 = t把这些候选映射连续回代到原文里,看它们能不能稳定地产生高频法语词,并最终拼出通顺句子。
用开头四个词把表补起来:
把前几个长词直接回代,明文会很快显形。把它按“已知字母 + 未知字母”的形式进行迭代。
拿文章开头前四个词进行验证

把已经得到的映射填进去:
b3a3d1 -> ?e?
c2b1e3d4d3d1 -> ??a?d?
a4e5c5b1e3c2a3d1 -> ????a?e?
b3a4b4e1e3b1a3d1 -> ????are?先看第一个词 b3a3d1 -> ?e?。文章开头是一个三字母词,第二个字母是 e。法语里常见的开头词可以是 les、des、ces、ses。但是只靠这一个词还不能定,先放着。
把前四个词连在一起看,目前只有这些形状:
?e? ??a?d? ????a?e? ????are?继续看第二个词。
c2b1e3d4d3d1 -> ??a?d?。如果最后两个坐标 d3d1 里面 d3 = d,那么这个词尾是 d?。法语形容词里非常常见的六字母词 grands 正好是:
g r a n d s
c2 b1 e3 d4 d3 d1这样能一次补出:
c2 = g
b1 = r
d4 = n
d1 = s有了 d1 = s,第一个词立刻变成:
b3a3d1 -> ?es在 ?es grands ouvrages 这个语境里,最顺的是 ces grands ouvrages。后续也有ai联网证明,于是:
b3 = c再看第三个词:
a4e5c5b1e3c2a3d1 -> ???rages它的尾巴已经确定是 rages,而且前面句子是:
ces grands ???rages到这一步就不需要盲测了,ai联网搜索一下:

a4e5c5b1e3c2a3d1 -> ouvrages于是补出:
a4 = o
e5 = u
c5 = v第四个词再回代:
b3a4b4e1e3b1a3d1 -> co??ares继续ai联网搜索:

b4 = m
e1 = p现在开头四个词就能完整读出来:
ces grands ouvrages compares如果再往后多看四个词,验证会更强:
e3e5 -> au
b3a4b1e1d1 -> corps
b2e5b4e3d2d4 -> humain
d1a3b4c3c4a3d4a1 -> semblent连起来就是:
ces grands ouvrages compares au corps humain semblent继续补出更多字母:
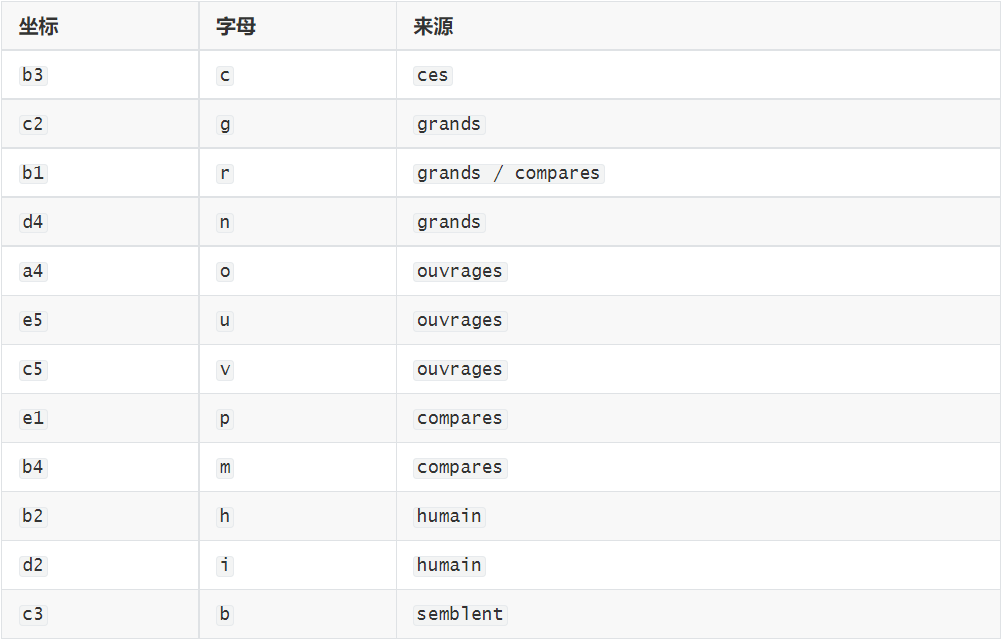
把已有映射回代到高频词里:
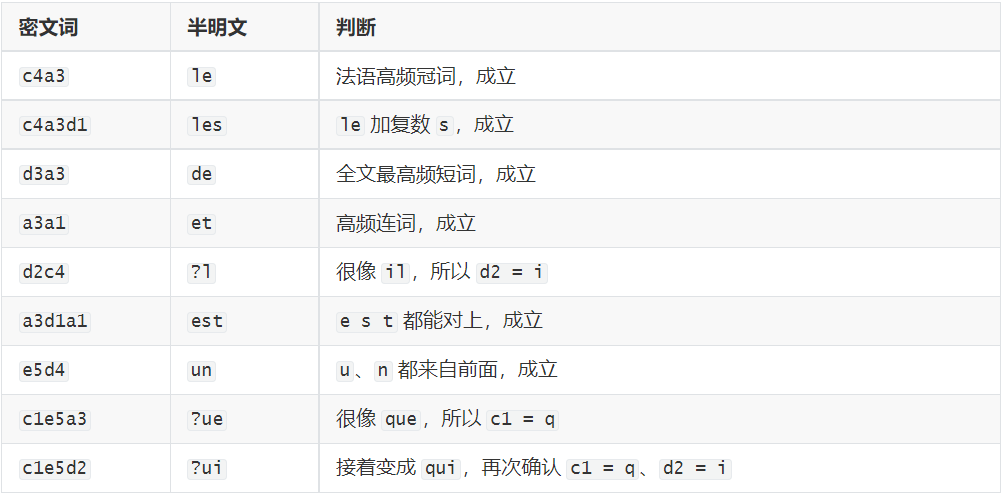
假如如果前面的 a3 = e、e3 = a、c4 = l 有一个错了,这里就不会连续冒出 le、les、de、et、est、un、que、qui 这么多正常法语词,所以前面的高频穷举目前没有问题。
votrec5a4a1b1a3 -> votre这个词其实大部分字母已经由 ouvrages 和 grands 带出来了:
c5 = v
a4 = o
a1 = t
b1 = r
a3 = ev-o-t-r-e 全部能对上,证明前面的 v/o/t/r/e 没有冲突。
frerese2b1a3b1a3d1 -> ?reres这个词的结构很特别:第 2 位和第 4 位都是 r,第 3 位和第 5 位都是 e,最后是 s。在文章主题里又经常谈到“兄弟”,所以 ?reres -> freres。
于是补出:
e2 = fmaintenantb4e3d2d4a1a3d4e3d4a1 -> ma?ntenant这里的判断更直观。b4 = m、e3 = a、d4 = n、a1 = t、a3 = e 已经有了,只剩中间的 d2。ai联网证明 ma?ntenant ->maintenant,所以:
d2 = i这个结论还会被 d2c4 -> il、c1e5d2 -> qui 反复验证。
toujoursa1a4e5a2a4e5b1d1 -> tou?ourst o u ? o u r s 这个形状非常明显,法语高频词就是 toujours,所以:
a2 = j到这里,常见字母基本齐了。剩下的 b、h、x、y、z 这类低频字母,是不可能一眼看出来的,法语生的话就当我没说过这句话,通常是在全文回代到九成可读以后,从个别词里补出来。笔者是没有任何法语基础的,某些词都是靠ai翻译得出的。
完整映射表:
最终得到的对应关系如下:
a1 -> t a2 -> j a3 -> e a4 -> o a5 -> z
b1 -> r b2 -> h b3 -> c b4 -> m b5 -> x
c1 -> q c2 -> g c3 -> b c4 -> l c5 -> v
d1 -> s d2 -> i d3 -> d d4 -> n d5 -> y
e1 -> p e2 -> f e3 -> a e5 -> u最终解密之后的明文:
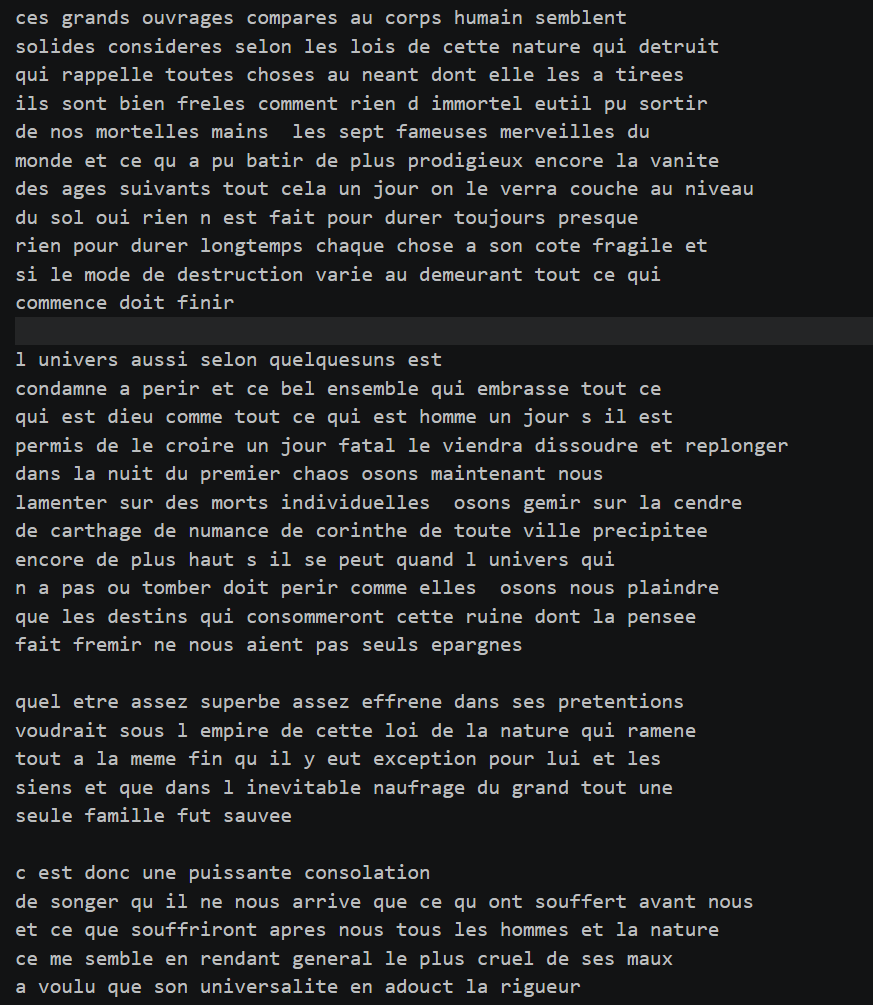
这道题给笔者的感觉就是像js逆向的字体反爬,都是通过映射即可解决。
本课程最终解释权归蚁景网安学院
本页面信息仅供参考,请扫码咨询客服了解本课程最新内容和活动










