多臂老虎机,又称为mab。
同一个环境,动作,状态下有可能返回1,有可能返回0。
也就是说环境反馈它不是一个固定的值。
可以假设为有五个函数,也就是相当于五种反馈,第一个函数返回1的概率是20%,返回0的概率是80%。
代码实现:
import numpy as np
import pandas as pd
class MultiArmedBandit:
def __init__(self, n_arms, true_rewards):
self.n_arms = n_arms
self.true_rewards = true_rewards
self.estimates = np.zeros(n_arms) # 每个臂的奖励估计
self.action_counts = np.zeros(n_arms) # 每个臂被选择的次数
def select_arm(self, epsilon):
if np.random.rand() < epsilon:
return np.random.randint(self.n_arms) # 探索
else:
return np.argmax(self.estimates) # 开发
def update_estimates(self, chosen_arm, reward):
self.action_counts[chosen_arm] += 1
# 更新奖励估计
self.estimates[chosen_arm] += (reward - self.estimates[chosen_arm]) / self.action_counts[chosen_arm]
def simulate_bandit(n_arms, true_rewards, n_rounds, epsilon):
bandit = MultiArmedBandit(n_arms, true_rewards)
rewards = np.zeros(n_rounds)
cumulative_rewards = np.zeros(n_rounds)
for round in range(n_rounds):
chosen_arm = bandit.select_arm(epsilon)
reward = np.random.normal(true_rewards[chosen_arm], 1) # 奖励是正态分布
bandit.update_estimates(chosen_arm, reward)
rewards[round] = reward
cumulative_rewards[round] = np.sum(rewards)
return cumulative_rewards
# 参数设置
n_arms = 5
true_rewards = [1.0, 1.5, 2.0, 0.5, 1.2] # 每个臂的真实奖励均值
n_rounds = 1000
epsilon = 0.1
cumulative_rewards = simulate_bandit(n_arms, true_rewards, n_rounds, epsilon)
results_df = pd.DataFrame({
'Round': np.arange(1, n_rounds + 1),
'Cumulative Rewards': cumulative_rewards
})
results_df类定义:MultiArmedBandit
n_arms 老虎机的数量
true_rewards 每个臂的真实平均奖励
estimates 目前认为每个臂的平均回报是多少,初始全为0。
action_counts 记录每个臂被拉了多少次,用于更新均值。
选择臂:select_arm(self, epsilon)
然后定义一个随机数。
以概率 ε 进行探索,也就是随机选一个臂,以概率 1 - ε 进行开发(选当前估计奖励最高的臂)。
比如说当 epsilon = 0.1:
10% 概率随机探索
90% 概率选估计最好的那一个
更新估计值:update_estimates()
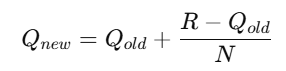
R 是这次的实际奖励;N 是该臂被选过的次数;Q 是对该臂期望奖励的估计。
模拟函数:simulate_bandit()
初始化一个 MultiArmedBandit 实例;
进行多轮(n_rounds)实验;
每一轮:
用 select_arm() 决定拉哪一台机器;
根据真实均值 true_rewards[chosen_arm] 生成一个服从正态分布的奖励;
用 update_estimates() 更新估计;
记录当前的奖励和累计奖励
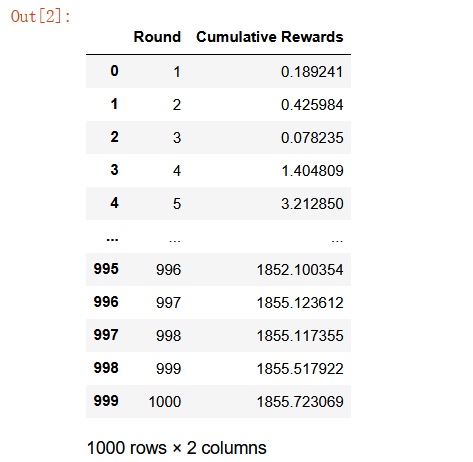
效果如图所示:
UCB算法是一种用于解决探索与利用问题的策略选择方法,广泛应用于多臂老虎机问题。
其核心思想是通过估计每个选项的潜在收益来平衡探索新选项和利用已知最佳选项 之间的权衡。
基本原理
探索与利用:
探索:尝试新的选项以获取更多的信息。
利用:选择当前已知的最佳选项以最大化收益。
UCB值计算: 对于每个选项,UCB算法计算一个上置信界值也就是UCB值,该值结合了成功率和探索因子。
计算公式:
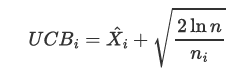
X_i 是选项 i 的成功率,即平均收益; n 是当前总的尝试次数; n_i 是选项 i 的尝试次数。
第一项是指当前已知的平均成功率;第二项是指置信区间,也就是越没试过的策略,这项越大;比如说你去饭堂吃饭,吃过 10 次的店你知道它一般,但没吃过的店你可能会想试一试,这就是 UCB 的探索机制。
应用场景 UCB算法广泛应用于在线广告推荐、A/B测试、动态定价、机器学习模型选择等领域,尤其是在需要实时决策和反馈的环境中。
ucb的通俗解释:一个左撇子,用手拿东西的时候,用右手的概率是20% ,用左手的概率是80%由于第一次选择的时候左右都会选,但是概率不同,选择不同手的频率就会影响两边ubc(可以理解为Q表)的值 那么我们就可以根据两边受频率影响的值动态调整我们是否选择高的那边的概率。
防火墙策略
假设有五个防火墙策略,并且拦截攻击的成功率都不一致。
但是在实际项目中,不用都写出成功率出来,毕竟只要知道哪个防火墙拦截的成功率高,那肯定优先选择那个防火墙。
现在是不知道概率多少。
import numpy as np
import pandas as pd
def check1(payload):
return np.random.rand() < 0.5 # 50%成功率
def check2(payload):
return np.random.rand() < 0.7 # 70%成功率
def check3(payload):
return np.random.rand() < 0.4 # 40%成功率
def check4(payload):
return np.random.rand() < 0.3 # 30%成功率
def check5(payload):
return np.random.rand() < 0.6 # 60%成功率
# 将所有检查函数放入列表中
check_functions = [check1, check2, check3, check4, check5]
# 定义防火墙策略选择器类
class FirewallPolicySelector:
def __init__(self, n_policies):
self.n_policies = n_policies
self.successes = np.zeros(n_policies)
self.attempts = np.zeros(n_policies)
def select_policy(self):
total_attempts = np.sum(self.attempts)
if total_attempts == 0:
return np.random.randint(self.n_policies) # 如果没有尝试过,随机选择
ucb_values = self.successes / (self.attempts + 1e-5) + np.sqrt(2 * np.log(total_attempts) / (self.attempts + 1e-5))
return np.argmax(ucb_values) # 选择UCB值最高的策略
def update(self, chosen_policy, success):
self.attempts[chosen_policy] += 1
self.successes[chosen_policy] += success
# 模拟防火墙策略优化过程
def simulate_firewall(n_policies, n_rounds):
policy_selector = FirewallPolicySelector(n_policies)
results = []
for round in range(n_rounds):
chosen_policy = policy_selector.select_policy()
payload = np.random.randint(0, 100) # 生成随机攻击样本
success = check_functions[chosen_policy](payload) # 使用选定的check函数
policy_selector.update(chosen_policy, success)
results.append((round + 1, chosen_policy, success))
results_df = pd.DataFrame(results, columns=['轮次', '选择的策略', '成功拦截'])
return results_df
# 参数设置
n_policies = len(check_functions) # 策略数量
n_rounds = 1000
# 运行模拟
results_df = simulate_firewall(n_policies, n_rounds)
# 筛选出成功拦截的部分
successful_results = results_df[results_df['成功拦截'] == 1]
# 输出每个策略的成功率
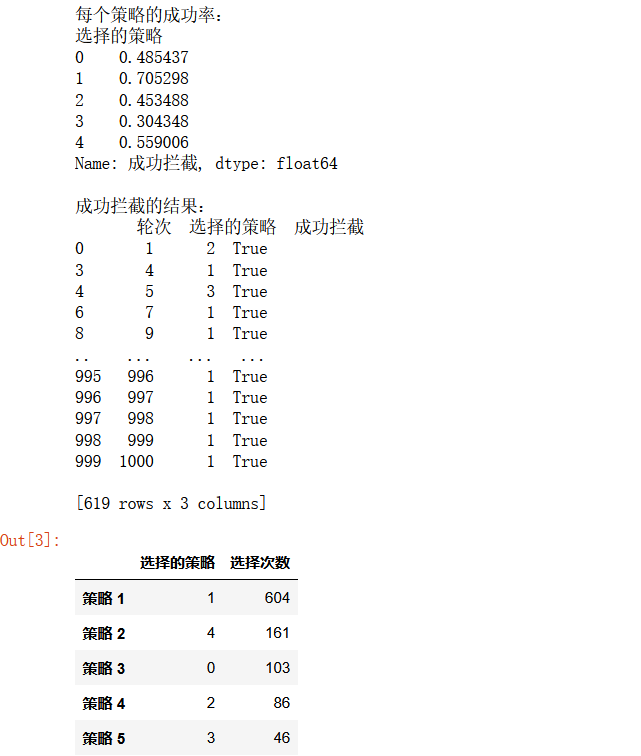
print("\n每个策略的成功率:")
print(results_df.groupby('选择的策略')['成功拦截'].mean())
# 显示成功拦截的结果
print("\n成功拦截的结果:")
print(successful_results)
# 统计每个策略的选择次数
policy_counts = results_df['选择的策略'].value_counts()
# 创建 DataFrame 显示所有策略及其选择次数
result_df = pd.DataFrame({
'选择次数': policy_counts
}).reset_index()
# 重命名列
result_df.columns = ['选择的策略', '选择次数']
# 设置行标题
result_df.index = [f'策略 {i+1}' for i in range(len(result_df))]
result_df防火墙策略选择器类 FirewallPolicySelector
n_policies: 策略数量;successes[i]: 第 i 个策略成功的次数;attempts[i]: 第 i 个策略被尝试的次数
策略选择核心 select_policy()
这里用的ucb计算公式,在上述已贴出。
模拟防火墙运行:simulate_firewall()
循环共执行 n_rounds,比如 1000 轮:
选择一个策略,然后模拟生成攻击,接着判断是否成功拦截,最后更新策略统计。
简单来说,这份代码就是模拟了一个基于UCB算法的自适应防火墙策略选择系统,它通过统计每个检测策略的历史成功率和尝试次数,自动在多轮攻击中选择最有效的策略,在“探索新方法”和“利用已知最优”之间取得平衡,最终趋向于选择拦截率最高的策略。
效果如图:
其实还有其他场景也适合,比如说什么恶意代码识别,邮箱识别,毕竟是策略选择。
假设现在有个角色A 通过mba模型实现强化学习下的优化钓鱼邮件内容。
还有一个角色B 通过Q-learning的方式实现强化学习下的钓鱼邮件内容识别。
当然也可以换成一边是恶意软件,一边杀毒软件,做一个养蛊哈哈。
整个流程就是攻击方不断发送不同类型的钓鱼邮件,防御方在识别的过程中逐渐学习,而攻击方也会记录哪些内容更容易成功,从而倾向选择这些高成功率内容。
import numpy as np
import pandas as pd
class PhishingContentOptimizer:
def __init__(self, contents, phishing_probabilities, epsilon=0.1):
self.contents = contents # 钓鱼邮件内容列表
self.phishing_probabilities = phishing_probabilities # 各内容被识别为钓鱼邮件的概率
self.epsilon = epsilon # 探索率
self.success_counts = np.zeros(len(contents)) # 各内容成功次数
self.total_counts = np.zeros(len(contents)) # 各内容尝试次数
def select_content(self):
if np.random.rand() < self.epsilon:
return np.random.choice(self.contents) # 随机选择
else:
success_rates = self.success_counts / (self.total_counts + 1e-5) # 避免除零
return self.contents[np.argmax(success_rates)] # 选择成功率最高的内容
def update(self, chosen_content, success):
index = self.contents.index(chosen_content)
self.total_counts[index] += 1
if success:
self.success_counts[index] += 1
class QLearningPhishingDetector:
def __init__(self, actions, learning_rate=0.1, discount_factor=0.9, exploration_rate=1.0):
self.q_table = {} # Q值表
self.actions = actions # 可采取的动作
self.learning_rate = learning_rate # 学习率
self.discount_factor = discount_factor # 折扣因子
self.exploration_rate = exploration_rate # 探索率
self.exploration_decay = 0.99 # 探索率衰减
def get_action(self, state):
if state not in self.q_table:
self.q_table[state] = [0] * len(self.actions)
if np.random.rand() < self.exploration_rate:
return np.random.choice(self.actions) # 探索
else:
return self.actions[np.argmax(self.q_table[state])] # 利用
def update_q_value(self, state, action, reward, next_state):
current_q = self.q_table[state]
max_future_q = max(self.q_table.get(next_state, [0] * len(self.actions)))
current_q[action] += self.learning_rate * (reward + self.discount_factor * max_future_q - current_q[action]) # 更新Q值
def decay_exploration(self):
self.exploration_rate *= self.exploration_decay
# 示例钓鱼邮件内容及其被识别为钓鱼邮件的概率
contents = [
"您的账户存在异常,请立即验证。",
"恭喜您获得奖品,请点击链接领取。",
"重要通知:请更新您的账户信息。",
"您有新的消息,请查看。",
"系统升级,请确认您的信息。",
]
# 各内容被识别为钓鱼邮件的概率
phishing_probabilities = {
contents[0]: 0.1,
contents[1]: 0.3,
contents[2]: 0.6,
contents[3]: 0.5,
contents[4]: 0.4,
}
# 初始化角色A(内容优化器)
optimizer = PhishingContentOptimizer(contents, phishing_probabilities)
# 初始化角色B(钓鱼邮件识别器)
actions = [0, 1] # 0: 正常邮件, 1: 钓鱼邮件
detector = QLearningPhishingDetector(actions)
# 预训练阶段
pretrain_steps = 50 # 预训练步骤数
for _ in range(pretrain_steps):
chosen_content = np.random.choice(contents) # 随机选择内容
action = detector.get_action(chosen_content) # 识别邮件
# 根据内容的钓鱼概率判断
success = np.random.rand() < phishing_probabilities[chosen_content] if action == 1 else False
reward = 1 if action == 1 and success else -1 # 奖励机制
detector.update_q_value(chosen_content, action, reward, chosen_content) # 更新Q值
detector.decay_exploration() # 衰减探索率
# 模拟钓鱼攻击过程
results = []
for _ in range(100): # 模拟100次钓鱼攻击
chosen_content = optimizer.select_content()
# 角色B识别邮件
action = detector.get_action(chosen_content) # 识别邮件
results.append({
'选择的内容': chosen_content,
'识别结果': '钓鱼邮件' if action == 1 else '正常邮件'
})
# 统计识别结果的成功率
for result in results:
if result['识别结果'] == '钓鱼邮件':
# 根据内容的钓鱼概率判断
success = np.random.rand() < phishing_probabilities[result['选择的内容']]
else:
success = False # 正常邮件识别为钓鱼邮件的成功率为0
# 更新角色A的成功与否
optimizer.update(result['选择的内容'], success)
# 更新角色B的Q值
reward = 1 if action == 1 and success else -1 # 奖励机制
detector.update_q_value(result['选择的内容'], action, reward, result['选择的内容']) # 更新Q值
detector.decay_exploration() # 衰减探索率
# 转换为DataFrame
results_df = pd.DataFrame(results)
# 输出结果
print(results_df)
# 统计每个内容的使用频率
content_counts = results_df['选择的内容'].value_counts()
most_used_content = content_counts.idxmax()
most_used_count = content_counts.max()
# 筛选出使用最多的内容的结果
most_used_results = results_df[results_df['选择的内容'] == most_used_content]
# 输出使用最多的内容
print(f"\n使用最多的内容: {most_used_content}, 使用次数: {most_used_count}")
print("\n使用最多内容的结果:")
print(most_used_results)
# 统计识别结果为正常邮件的百分比
normal_email_count = results_df[results_df['识别结果'] == '正常邮件'].shape[0]
total_count = results_df.shape[0]
normal_email_percentage = (normal_email_count / total_count) * 100
print(f"\n识别结果为正常邮件的百分比: {normal_email_percentage:.2f}%")钓鱼内容优化器 PhishingContentOptimizer
contents: 所有钓鱼邮件的模板内容
phishing_probabilities: 每种内容被识别为钓鱼的概率,也就是被识破的难度
epsilon: ε-贪婪算法中的“探索率”,比如 0.1 意味着 10% 概率随机探索
success_counts: 各邮件“成功骗过检测”的次数
total_counts: 每个内容被使用的次数
选择内容 select_content
每轮发送邮件前,优化器根据历史成功率决定发哪种内容:
90% 概率选择成功率最高的邮件
10% 概率随机选一个探索新的可能
这样攻击方会逐渐聚焦在最有效的邮件内容上。
钓鱼邮件检测器 QLearningPhishingDetector

更新 Q 值
update_q_value
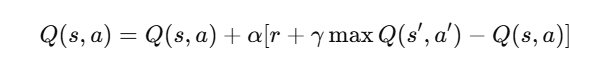
在状态 s 采取动作 a 后,得到奖励 r,下一状态 s' 的最大潜在价值是 max_future_q,于是把当前的 Q 值往新的期望值方向更新一点。
预训练阶段,让检测器先学习
模拟 50 封训练邮件,让检测器初步学会识别钓鱼概率高的邮件。
奖励逻辑:
检测为钓鱼且确实钓鱼 → 奖励 +1
否则 → 惩罚 -1
如果检测器判断为“钓鱼邮件”,就按对应概率看它是否真识别成功, 否则认为识别失败。
然后,攻击方更新该邮件的成功率,防御方更新Q值,探索率继续衰减。
这里其实还有个预训练,先让钓鱼邮件识别器跑起来,学习里面一些东西,分辨出哪个是钓鱼邮件,哪个是正常邮件。
然后再去模拟钓鱼邮件攻击的过程,结果如下图所示:

结果看起来比较发散,没有那么真实,其实可以把Q-Learing算法那一部分改为神经网络。
GAN网络其实就是Ai和Ai之间对打的过程。
本课程最终解释权归蚁景网安学院
本页面信息仅供参考,请扫码咨询客服了解本课程最新内容和活动











