给组里的本科生讲一讲恶意软件,以及如何识别恶意软件。
注:这里写得很简陋,只挑笔者不熟悉的部分写,具体学习还是得详看官方文档。
卷积神经网络(CNN)是一种深度学习模型,特别适用于处理图像和视频等数据。
CNN包括:卷积层、激活层、池化层、全连接层。
CNN的工作流程:
1.输入层:接收原始数据(如图像)
卷积层:提取特征,生成特征图
激活层:引入非线性
池化层:下采样,减少维度
重复步骤 2-4:多次卷积和池化以提取更高层次的特征.
全连接层:展平特征图并进行分类
输出层:输出预测结果
感受野是卷积神经网络中一个重要的概念,指的是网络中某一层的一个神经元所能“看到”的输入区域。
换句话说,感受野描述了网络中某个特征图位置的神经元对输入图像的哪些部分有响应。
单层感受野:对于卷积层,感受野的大小可以通过以下公式计算:
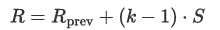
(R) 是当前层的感受野大小, R prev是前一层的感受野大小,(k) 是卷积核的大小,(S) 是步长。
说白了就是决定模型到底是看得宏观一点,还是看得微观一点,这主要还是取决于数据集,数据集提取出来的数学特征,是细节上的能够具体表明的数学特征。
还是比较抽象的数学特征。
比较抽象比较宏观的话,就可以用大一点的感受野。
感受野的影响:
特征提取能力: 较大的感受野可以捕捉到更大范围的上下文信息,有助于提取全局特征,但是准确度可能就会下降;较小的感受野则适合捕捉局部细节,判断的准确度就会更高,但是就不能理解更高维度的内容。
模型性能: 在某些任务中,较大的感受野可能会提高模型的性能,尤其是在处理复杂场景时。
设计选择: 在设计CNN时,可以通过选择合适的卷积核大小、步长和层数来控制感受野的大小,以适应特 定任务的需求。
注意:这里放出的代码都不是完整的,只截取重要部分代码。
这里收集一些windows api的调用序列,观察这个软件中调用哪些api,来判断这个软件是不是恶意软件。
windows_api_list = [
"CreateFileA", "CreateFileW", "ReadFile", "WriteFile", "CloseHandle",
"GetLastError", "SetLastError", "VirtualAlloc", "VirtualFree",
"CreateThread", "ExitThread", "WaitForSingleObject", "GetModuleHandleA",
"GetProcAddress", "LoadLibraryA", "LoadLibraryW", "FreeLibrary",
"GetModuleFileNameA", "GetModuleFileNameW", "MessageBoxA", "MessageBoxW",
"CreateEventA", "CreateEventW", "SetEvent", "ResetEvent", "WaitForMultipleObjects",
"OpenProcess", "TerminateProcess", "ReadProcessMemory", "WriteProcessMemory",
"CreateProcessA", "CreateProcessW", "GetExitCodeProcess", "ShellExecuteA",
"ShellExecuteW", "FindFirstFileA", "FindNextFileA", "FindClose",
"DeleteFileA", "DeleteFileW", "MoveFileA", "MoveFileW",
"CopyFileA", "CopyFileW", "CreateDirectoryA", "CreateDirectoryW",
"RemoveDirectoryA", "RemoveDirectoryW", "GetFileSize", "SetFilePointer",
"FlushFileBuffers", "GetFileInformationByHandle", "SetEndOfFile",
"GetFileTime", "SetFileTime", "CreateMutexA", "CreateMutexW",
"ReleaseMutex", "OpenMutexA", "OpenMutexW", "CreateSemaphoreA",
"CreateSemaphoreW", "ReleaseSemaphore", "OpenSemaphoreA", "OpenSemaphoreW",
"CreatePipe", "ReadFileEx", "WriteFileEx", "CancelIo",
"GetOverlappedResult", "CreateIoCompletionPort", "PostQueuedCompletionStatus",
"GetQueuedCompletionStatus", "SetEvent", "ResetEvent", "CreateFileMappingA",
"CreateFileMappingW", "MapViewOfFile", "UnmapViewOfFile", "VirtualQuery",
"VirtualQueryEx", "GetSystemInfo", "GetSystemTime", "SetSystemTime",
"GetTickCount", "Sleep", "GetCurrentProcessId", "GetCurrentThreadId",
"GetCommandLineA", "GetCommandLineW", "GetEnvironmentVariableA",
"GetEnvironmentVariableW", "SetEnvironmentVariableA", "SetEnvironmentVariableW",
"CreateProcessAsUserA", "CreateProcessAsUserW", "ImpersonateLoggedOnUser",
"RevertToSelf", "OpenThreadToken", "SetThreadToken", "DuplicateTokenEx",
"AdjustTokenPrivileges", "GetTokenInformation", "SetTokenInformation",
"CreateRemoteThread", "GetExitCodeThread", "WaitForInputIdle"
]收集完之后,把这些windows api变成numpy数组 类似[0,1],每一个位置代表一个独特的windowsapi函数,位置上的值代表这个函数有没有被调用。
然后我们要接收.exe软件,使用pefile.PE这个python的第三方库,从其导入表里面把windows api提取出来,放入列表。
然后遍历.exe软件提取到的的windows api,是否在事先写好的windows api列表中,如果找到,就找到对应的索引号,写成1。
def extract_api_calls(exe_path):
pe = pefile.PE(exe_path)
api_calls = []
# 遍历导入表
for entry in pe.DIRECTORY_ENTRY_IMPORT:
for imp in entry.imports:
api_calls.append(imp.name.decode('utf-8') if imp.name else None)
return api_calls
def create_api_vector(api_calls):
vector = np.zeros(len(windows_api_list), dtype=int)
for api in api_calls:
if api in windows_api_list:
index = windows_api_list.index(api)
vector[index] = 1
return vector这里的恶意软件的数据集可以利用微步的api,去爬取恶意样本。
正常软件也同理。
把正常软件标签贴为0,恶意的程序标签为1。
def whitelist(whitedir):
labels = []
features = []
# 获取文件夹中所有的 EXE 文件
for filename in os.listdir(whitedir):
if filename.endswith('.exe'):
one_feature = read_one_file(os.path.join(whitedir, filename))
features.append(one_feature)
labels.append(0) # 标签为 0
# 将 features 转换为 numpy 数组
features_array = np.array(features)
return features_array, np.array(labels)
def blacklist(whitedir):
labels = []
features = []
# 获取文件夹中所有的 EXE 文件
for filename in os.listdir(whitedir):
if filename.endswith('.exe'):
one_feature = read_one_file(os.path.join(whitedir, filename))
features.append(one_feature)
labels.append(1) # 标签为 1
# 将 features 转换为 numpy 数组
features_array = np.array(features)
return features_array, np.array(labels)
# 读取白名单和黑名单特征
whitelist_features, whitelist_labels = whitelist("./data/normal_file")
blacklist_features, blacklist_labels = blacklist("./data/virus_file")数据处理好之后,开始创建模型。
import tensorflow as tf
import vec_data
# 创建 CNN 模型
model = tf.keras.Sequential([
tf.keras.layers.Conv1D(32, kernel_size=3, activation='relu', input_shape=(vec_data.features.shape[1], 1)),
tf.keras.layers.MaxPooling1D(pool_size=2),
tf.keras.layers.Conv1D(64, kernel_size=3, activation='relu'),
tf.keras.layers.MaxPooling1D(pool_size=2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(2, activation='softmax') # 二分类
])模型比较简单,一个卷积,一个池化,再一个卷积,一个池化,然后就展平,全连接,全连接。
所有神经网络的第一层一定都是数据输入层,不管是什么神经网络算法,都得在第一层写个input_shape表示输入的数据。
接下来是模型的参数:
train_param = {"epoch": 50, "batch_size": 32}
model_compile_param = {
"optimizer":'adam',
"loss":'sparse_categorical_crossentropy',
"metrics":['accuracy']
}第一个是训练次数 50 和每一次训练读到的数据的最小量 32。
第二个是模型编译的参数,adam编译器,损失函数,评分机制。
然后是模型训练:
import tensorflow as tf
import model_struct
import vec_data
import model_param
model_struct.model.compile(optimizer=model_param.model_compile_param["optimizer"],
loss=model_param.model_compile_param["loss"],
metrics=model_param.model_compile_param["metrics"])
print(model_struct.model.summary())
model_struct.model.fit(vec_data.features,
vec_data.labels,
epochs=model_param.train_param["epoch"],
batch_size=model_param.train_param["batch_size"])
model_struct.model.save("my_cnn.keras")先把模型编译出来,然后就做训练,最后把模型保存下来。
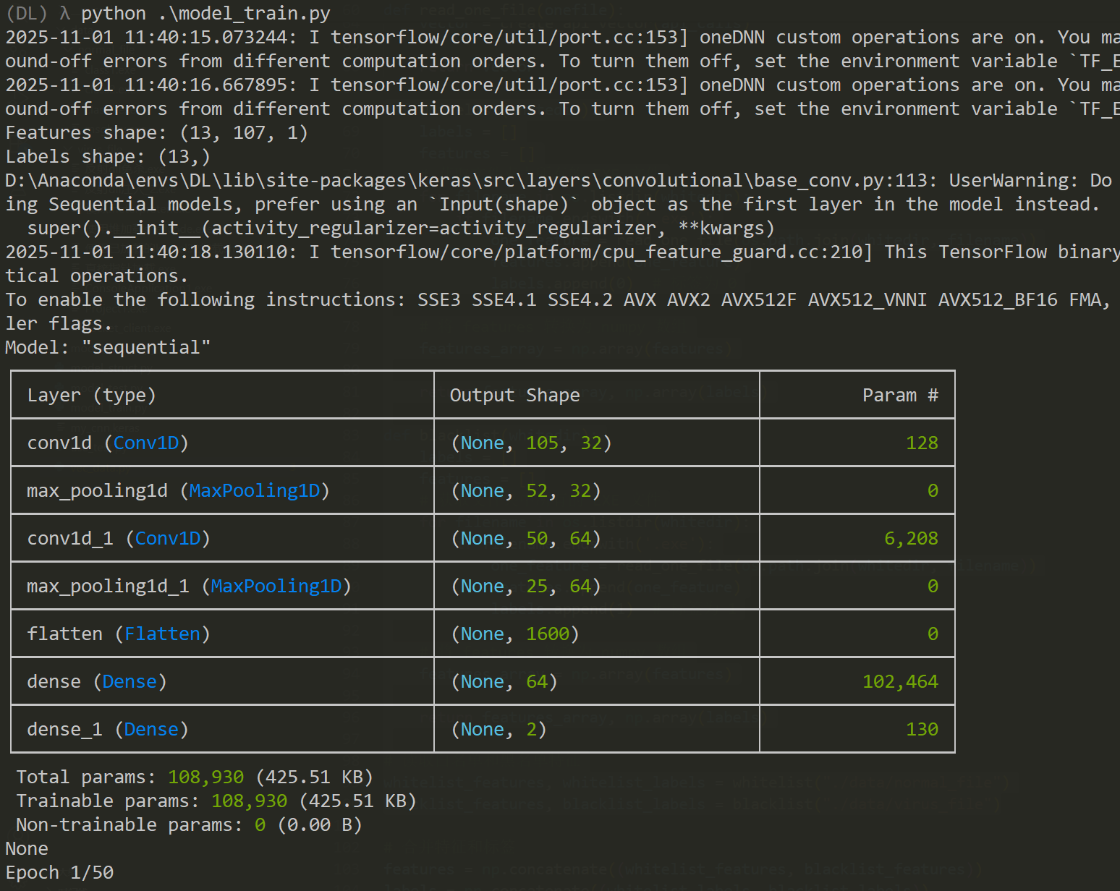
显示的神经网络的形状,卷积层向下输出32,到展平那里输出已经是1600了。
下面是训练50次:
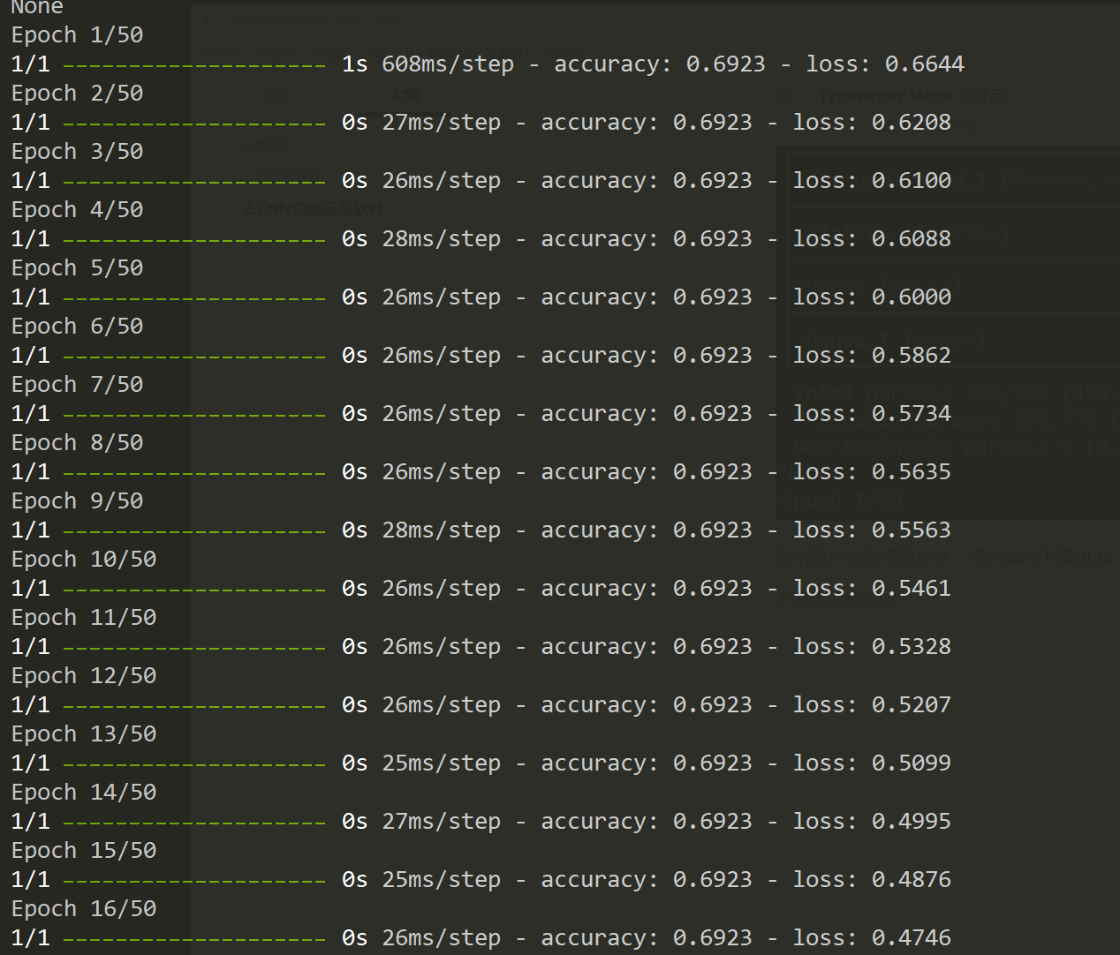
可以看到损失函数的大小和正确率。
虽然最后正确率显示有92%,但是因为实际的样本数量较少,训练次数又较多,就会有过拟合的问题,实战不行。
所以还得去多找一些样本,VT和微步。
模型完成之后,就来用模型去测试了。
这里写个了简单弹窗程序:
void main() {
MessageBoxA(NULL,"aaaa","bbbb",MB_OK);
}编译出.exe文件后丢给模型去测试:
import tensorflow as tf
import numpy as np
import vec_data
def predict_exe(exe_path, model):
# 提取 API 调用
api_calls = vec_data.extract_api_calls(exe_path)
# 创建特征向量
feature_vector = vec_data.create_api_vector(api_calls)
# 调整输入形状
feature_vector = feature_vector.reshape(1, feature_vector.shape[0], 1) # (1, 特征长度, 1)
# 进行预测
prediction = model.predict(feature_vector)
# 获取预测结果
predicted_class = np.argmax(prediction, axis=1)
return predicted_class[0]
model = tf.keras.models.load_model('./my_cnn.keras')
# 示例用法
exe_path = "../Project1/x64/Release/Project1.exe"
predicted_label = predict_exe(exe_path, model)
print(f'Predicted label: {predicted_label}') # 0 表示白名单,1 表示黑名单将目标.exe文件导入,然后提取API,创建特征向量,调整输入形状,进行预测结果会是个矩阵,所以最后用np.argmax这个参数最大的矩阵拿来做标签预测。
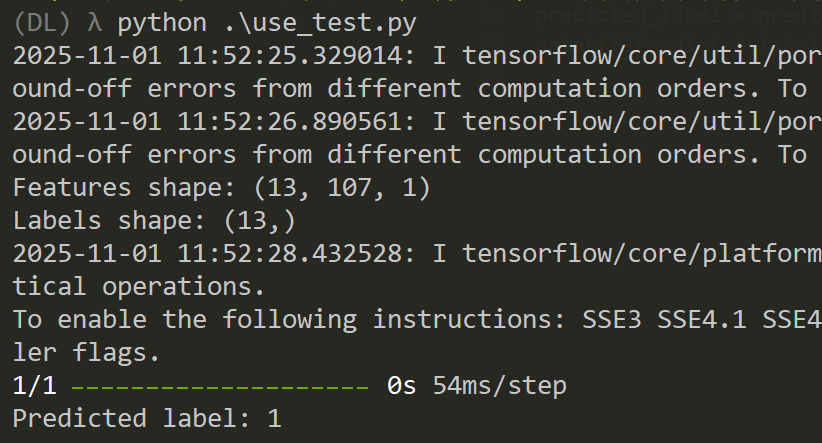
它显示的是1,也就是个恶意软件,但是这其实只是个正常的弹窗程序罢了。
所以这里其实就存在问题,样本数量太少了,导致实战不行。
不过模型的构造和训练方法是一样的,只需要增加样本数量和根据自己电脑性能调整训练次数,就可以有令人满意的结果。
补充:用windows api来做恶意软件检测其实算是比较取巧,因为在免杀中很多恶意软件是可以隐藏的导入表函数的,然后还有很多函数可以替换达到同样的效果。
还有就是现在很多恶意软件都会把自己的api调用变成一个正常应用程序,也就是说正常程序会调用的windows api,恶意软件也会用,所以拿windows api 来做恶意软件检测在实战中效果应该是不太理想的。
像360,火绒之类的大厂 会用ast ,也就是控制流程,if-else这些东西,做成numpy数组;
或者是直接把shellcode这类16进制数放入模型中,比如说提取text段shellcode放入数组。
当然长度可能会不一样,所以需要定义一下长度(1.1024*1024),把shellcode放入到每一个位置中去,如果小于定义长度就拿0去填充。
如果大于就切掉多余的部分。
或者直接多个模型多个特征来综合判断是不是恶意软件。
本课程最终解释权归蚁景网安学院
本页面信息仅供参考,请扫码咨询客服了解本课程最新内容和活动










