0x01 前言
本文将介绍如何利用机器学习技术检测安卓恶意软件,在前文会介绍相关基础知识,在后文则以实战为导向,介绍如何使用支持向量机检测安卓恶意软件,以及通过可解释性技术解释模型的决策结果,最后介绍如果对该模型发动对抗样本攻击。
在机器学习中,支持向量机(英语:support vector machine,常简称为SVM,又名支持向量网络)是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。
给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。
相关实验:<支持向量机检测DGA>:https://www.yijinglab.com/expc.do?ec=ECIDd5fb-5379-4f4b-862e-db7ab18b3a19(了解支持向量机的原理,学习SVM是怎么应用于检测DGA的。)
接着介绍本文用到的可解释性技术,来自于[2][3]两篇论文。
我们使用的数据集是Drebin,该数据集包含来自 179 个不同恶意软件家族的 5,560 个应用程序,样本是在2010年8月至 2012年10月期间收集的,由MobileSandbox 项目提供。其主页为:https://www.sec.cs.tu-bs.de/~danarp/drebin/

数据集的每个特征都是一个布尔变量,0表示不存在该特征,1表示存在该特征。
如下所示:

安卓样本(apk文件)在特征空间中表示为向量,然后用一组带有标签的数据集进行训练,来区分良性样本和恶意样本。在测试时,则用训练得到的分类器判别样本文件。如果其输出f(x)>0,则将其归类为恶意样本,否则归类为良性样本。我们希望利用可解释性技术解释模型做出对应决策的理由。

以前的可解释性技术关注梯度,更一般的说法就是围绕输入点x的线性近似值给解释技术提供了有用的信息。设f是与预测类别相关的置信度,其认为与局部梯度 ∇f(x) 的最大绝对值相关的那些特征识别是最能影响决策结果的特征。然而,对于稀疏数据(比如安卓恶意软件)来说,那些方法给出的最有影响力的特征往往不在给定的样本中,从而难以解释相应的预测结果。
因此,我们采用不同的方法。我们将梯度 ∇f (x) 投影到 x 上以获得特征相关(feature-relevance)向量 ν = ∇f(x) · x ∈ Rd,其中 · 表示元素乘积。然后我们将 ν 归一化为一元 l1 范数,即 r =v/||v|,以确保只有 x 中的非空特征被识别为与决策结果相关。 最后,可以将 r 的绝对值按降序排列以识别对决策结果最具影响的特征。
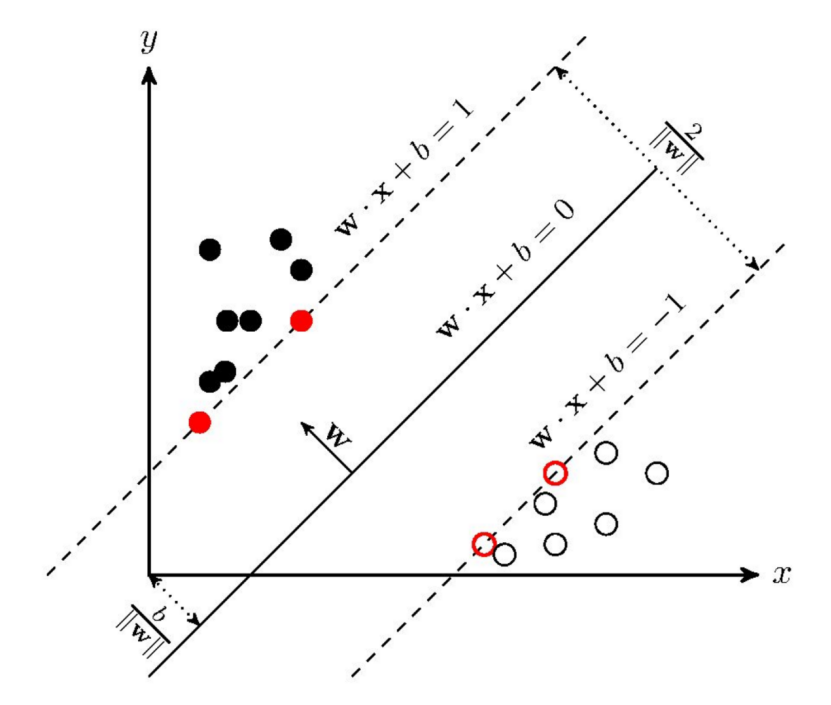
应用提出的解释性技术,下表中给出了SVM(顶行)和 RF(底行) (i) 良性样本(第一列),(ii)SM SWA TCHER 家族的恶意软件样本(第二列),以及 (iii) PL ANKTON家族的恶意软件样本(第三列)的最能影响判决结果的前10个特征,并给出了每个特征在 BENING (pB ) 和恶意软件 (pM ) 中存在的可能性。
然后介绍本文用到的对抗样本技术,来自于[4][5]两篇论文。
我们可以将生成的对抗样本形式化为:
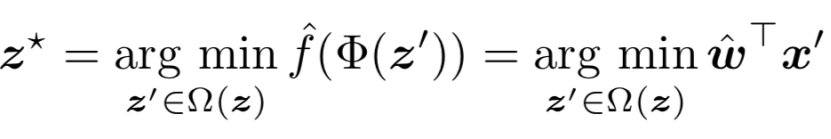
其中,x’是与生成的对抗样本z’相关的特征空间,wˆ 是攻击者估计的权重向量。
这个式子本质上告诉攻击者应该修改哪些特征以最大程度地降低分类函数的值,即最大化逃避检测的概率。注意,根据操作约束 Ω(z)(例如如果特征值是有界的),要操作的特征集对于每个恶意样本通常是不同的。
攻击者的目标是最小化上面的式子,但是对于每个特征独立地估计 wˆ 的每个分量为:
![]()
这相当于鼓励攻击者添加(删除)在良性样本中更频繁出现(不存在)的重要特征,使恶意样本的概率分布更接近良性数据的概率分布。
在本部分最后,再捎带介绍后文会提到的两个概念。
F1分数:
F1分数(F1 Score)是统计学中用来衡量二分类模型精确度的一种指标。 它同时兼顾了分类模型的精确率和召回率。 F1分数可以看作是模型精确率和召回率的一种调和平均,它的最大值是1,最小值是0。
ROC曲线:
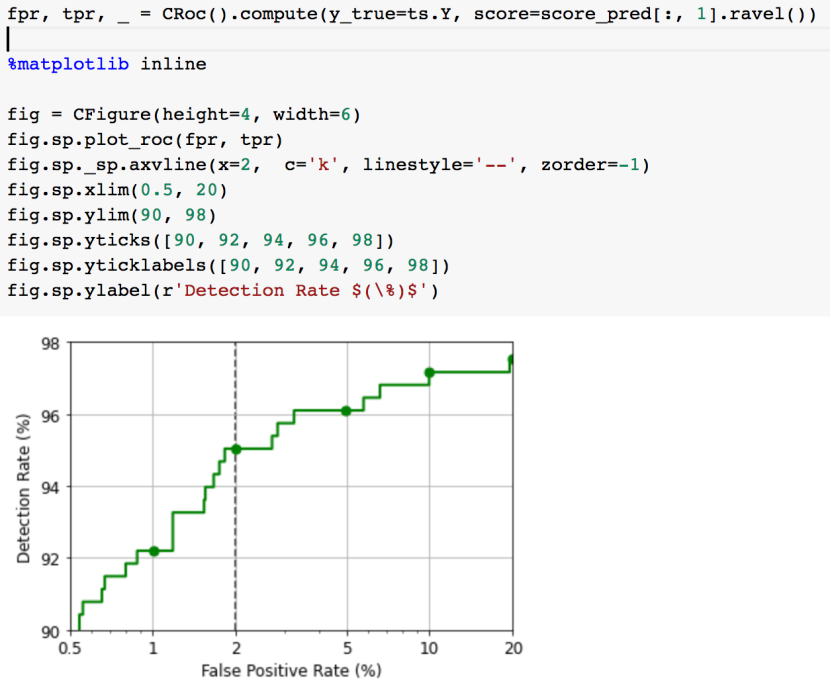
ROC 曲线(接收者操作特征曲线)是一种显示分类模型在所有分类阈值下的效果的图表。该曲线绘制了以下两个参数:真正例率TPR(在我们下面的实战中,就是恶意样本的检出率),假正例率FPR。
我们下载该数据集并解压:
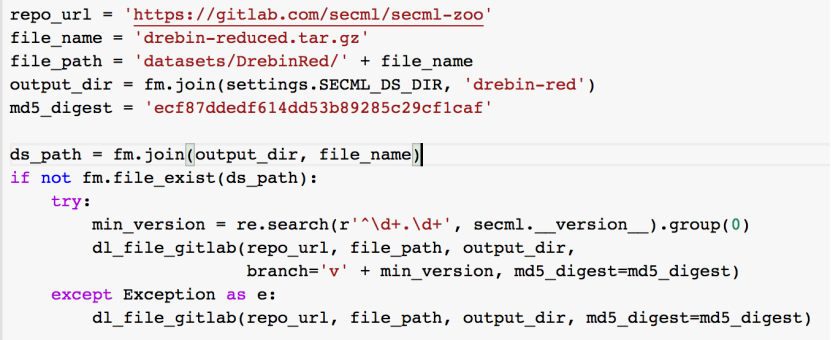
简单查看一下数据:

可以看到共下载了12550个样本,其中良性样本数量为12000,恶意样本数量为550。
我们使用支持向量机对其进行检测,首先用一半的数据集作为训练集,在其上进行训练:

其中,CClassifierSVM类的定义如下:
训练完成后打印其F1分数:

绘出ROC曲线:
接着我们来尝试使用XAI技术(可解释性AI)来解释训练得到的模型是以什么为依据将样本判定为良性或恶意。
我们使用基于梯度的解释方法:

CExplainerGradientInput类定义如下,我们在下面会用到其explain方法:
我们尝试对于一个良性样本和一个恶意样本,给出解释并分别列出对决策结果最大的前10个特征。
先来看对良性样本的解释:
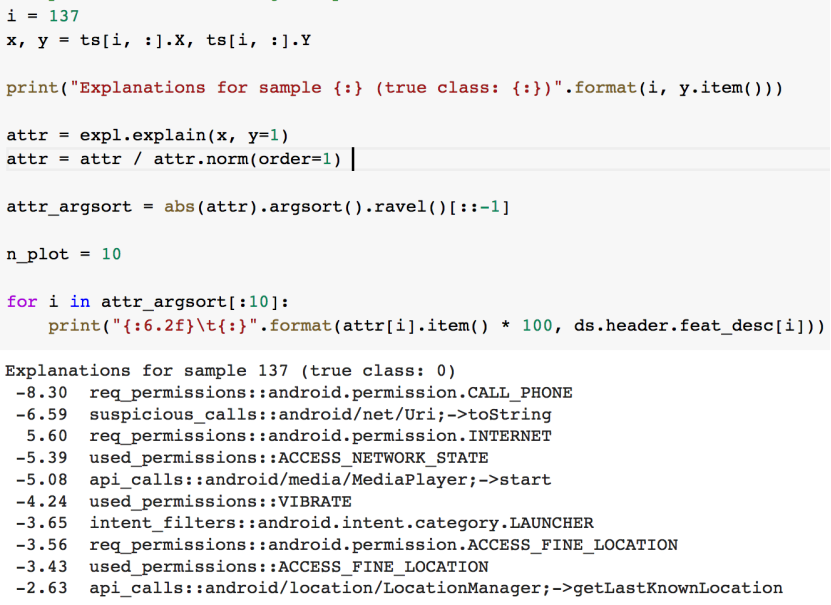
这里的true class:0,是说该样本为良性样本。对应地,下图中true class:1则说明其为恶意样本。
我们来看看返回的结果,负号说明这些特征是与决策结果负相关,或者换句话说,如果出现这些特征,那么样本是良性的可能性大。
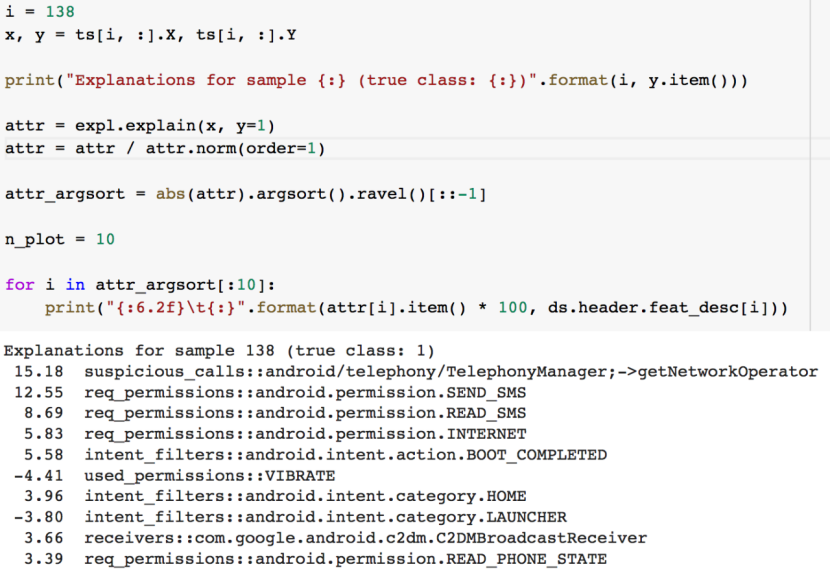
从上图可以看到与之前相反的结果,大多数特征具有正相关的值,这意味着,出现了这些正相关的特征,则样本极有可能是恶意的。
前面我们在检查数据的时候已经知道,这批样本共有1227080个特征。而从此处的结果可以看到,打印出的前10个特征已经占据了50%左右的相关性了,说明该机器学习模型倾向于将大部分权重分配给一组小的特征。
如果攻击者发现了这一点,这时候只需稍微改动恶意样本中正相关性较大的特征,就能欺骗模型将其分类为良性样本。当然实际中不需要手动去修改,我们还有对抗样本的技术,可以自动修改特征来欺骗分类器。
我们这里使用带线性搜索的投影梯度下降技术来创建可以对抗检测安卓恶意软件的SVM分类器的对抗样本。这里需要注意,和图片不同,在生成图片的对抗样本时,基本是不受约束的,图片不论怎么修改,还是一张图片。但是对于程序来说,添加或者删除某些特征,可能程序就不可用了。比如我们在一个恶意程序上做对抗样本,如果改动幅度过大,可能生成的对抗 样本确实被分类器认为是良性的,但是该对抗样本可能已经失效的,即无法执行恶意行为,那么就失去了对抗样本的意义。
我们的经验就是一般不要轻易删除某些特征,尤其是不要删除manifest组件,因为容易破坏程序的功能。相对地,添加特征更安全一些,比如添加权限就不会影响任何现有功能。
我们来设置攻击参数:

这里主要关注distance和y_target。
distance我们设为l1,因为每个特征是一个布尔变量(0或1),我们希望在一次迭代时只改变一个特征(从0到1,或者从1到0)。
y_target设为0,是希望生成的对抗样本被归类为良性。(这里我们指定了攻击目标,在对抗样本中称为定向攻击)
接着发动攻击:
![]()
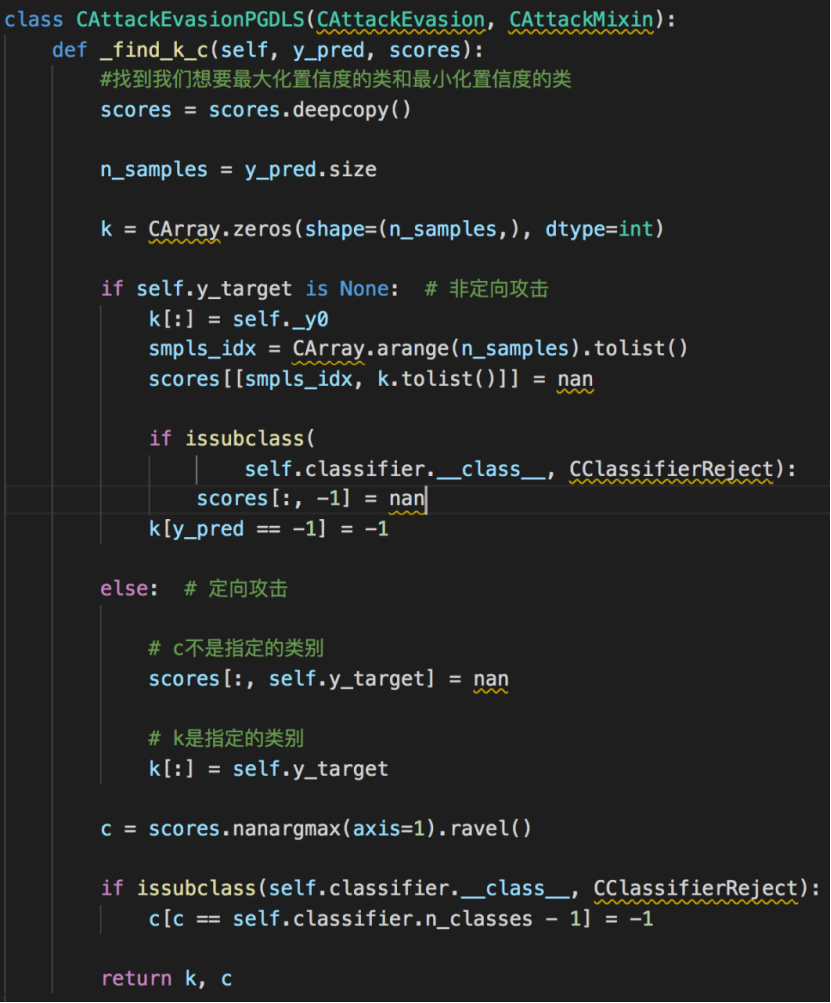
该类定义如下:
画出攻击后的情况:
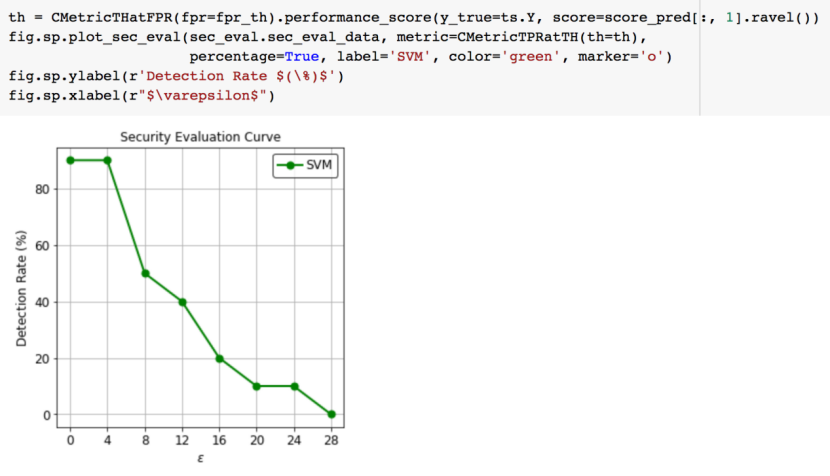
从图中可以看到,在改变了不到10个特征之后,恶意样本的检出率就低于50%了,证实了对抗样本攻击的有效性。
相关课程:《基于机器学习的网络安全应用实践》
(学习如何将机器学习与网络安全结合起来,使用机器学习来辅助网络安全问题的解决。)
1.https://zh.wikipedia.org/wiki/%E6%94%AF%E6%8C%81%E5%90%91%E9%87%8F%E6%9C%BA
2.Not just a blackbox: Learning important features through propagating activation differences
3.Explaining Black-box Android Malware Detection
4.Is Deep Learning Safe for Robot Vision?Adversarial Examples against the iCub Humanoid
5.Yes, Machine Learning Can Be More Secure!A Case Study on Android Malware Detection
6.《机器学习》、《深度学习》
本课程最终解释权归蚁景网安学院
本页面信息仅供参考,请扫码咨询客服了解本课程最新内容和活动










